I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer??
Properties?? Tools?? Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
Stan Brown <someone@example.com> wrote:t response that
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instan
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
On 10/11/25 3:02 PM, Stan Brown wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hardIf you do a full format on a 2tb disk, make sure you don't mind keeping
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
the PC on for days and don't have power brown outs.�� Damn that would take
a good bit of time.
On 2025/10/11 21:11:15, VanguardLH wrote:
Stan Brown <someone@example.com> wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
Nothing the _computer_ can do will directly tell you about surface
errors, because the electronics in the drive itself will substitute
spare sectors for any known to be bad - so anything the computer does
will get back "no bad sectors here" - until the drive runs out of spare sectors, by which time it's time to replace it anyway.
The only thing that will show you when swapping is happening is
something that checks the _speed_ of access to all of the drive:
although all sectors will read back as OK, if the drive has to
substitute sectors from the spare pool, and has to move the heads to do
so, it will take longer for those particular sectors.
The only tool I know of that will do this is the old free version of
HDTune (and I don't know if that will work under W10, though I think it
will - Paul?). The free one is well down the download page, and many
years old. (If you can't find it, ask here, and one of us may be able to
send it to you.)
If it works, you should get a smooth curve, similar to https://255soft.uk/temp/HDTune_1.png and https://255soft.uk/temp/HDTune_2.png, showing the speed of access across
the disc surface - it's fastest at the start (outside of the platters).
Any dud sectors will be shown as a downward spike in the curve. But
don't worry when you get some such spikes! Because it is ancient
software, its speed test gets interrupted by any activity that Windows
does while it's running - which shows as a dip in speed at whatever
sector HDTune is checking at that moment. So you save the plot (click on
the picture of the floppy), and run it a second time and save _that_ -
then flick back and forth between the two saved images. (I find
IrfanView ideal for this, but use whatever you use to look at images, as
long as it can flick back and forth easily between two.) Any downward
spikes should be in _different places_ on the two plots, because if
HDTune was interrupted by Windows doing something, that shouldn't happen
at the same point both times. (Compare my two samples to see what I mean.)
You need to do this with the drive being tested actually plugged into
the motherboard, not in an external USB enclosure. (I presume it's a
SATA drive.) HDTune will ignore any partitioning - it tests the whole
drive, regardless; I don't even _think_ it has to be formatted. (Make
sure - drop-down list top left - that it's testing the right drive,
though, not your existing drive. Though if that's a real HDD, you could always check that too! It doesn't corrupt what's on the drive, if anything.)
Good luck, and hope it works for you!
If anyone else knows any other way to actually check for bad sectors
that won't be fooled by the drive's electronics into not seeing any,
please share. (HDTune doesn't see bad sectors either, but its test of
the speed of access to them gives an _indication_ when swapping is happening.)
On 2025/10/11 21:11:15, VanguardLH wrote:
Stan Brown <someone@example.com> wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer??
Properties?? Tools?? Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
Nothing the _computer_ can do will directly tell you about surface
errors, because the electronics in the drive itself will substitute
spare sectors for any known to be bad - so anything the computer does
will get back "no bad sectors here" - until the drive runs out of spare sectors, by which time it's time to replace it anyway.
If you see pending allocations in SMART that don't reduce to zero after
a reboot then the spare sectors have been used up.
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
On 2025-10-12 10:26, VanguardLH wrote:
If you see pending allocations in SMART that don't reduce to zero after
a reboot then the spare sectors have been used up.
Huh, no.
Reallocation happens when writing to a bad sector. If you only read to it, the bad sector remains active.
On 2025-10-11 21:02, Stan Brown wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
On Sun, 10/12/2025 9:15 AM, Carlos E.R. wrote:
On 2025-10-12 10:26, VanguardLH wrote:
If you see pending allocations in SMART that don't reduce to zero after
a reboot then the spare sectors have been used up.
Huh, no.
Reallocation happens when writing to a bad sector. If you only read to it, the bad sector remains active.
We don't know exactly how it works, because it isn't an honest
reporting system to begin with.
Reallocated isn't a linear reporting system. To make up
an example, say a disk has room for 103500 reallocations.
The disk might decide, for the first 100000 reallocations,
it will report... nothing. The raw data field will read 0.
Then, for the remaining 3500 reallocations, the raw data
will increment from 0..3500 .
The reason for doing this,
is to prevent customers from "cherry picking" drives and
doing retail returns "until they get a good one".
It means you could send a worn out disk to a customer as
a "refurb" on a warranty return, and the indicator still
reads 0. And it reads 0 without resetting any statistics
or cheating.
The thing is, there are a number of bad sectors during
surface certification. These will obviously be spared out.
If there are too many, the product will be rejected, and
maybe the robot will put a new stack on the thing or something.
It's unlikely they just shred drives which don't pass. And the
disk manufacturer has things like robots for taking drives
apart (recycling disassembly).
The platters are certified somehow, when made at the platter
factory. The platter factory can be a separate facility from
the disk drive factory, and they polish plated-up platters
and do some sort of scan so that only "perfect discs" with
a blemish free surface, are sent to Seagate, WD, and Tosh. There
are thick platters for 4TB drives and thin platters for 24TB drives.
The materials could be different. Al substrate in one, glass
in the other type. The active layers are established via plating.
They try not to have too many platter types in production,
so it doesn't become a zoo. It's hard to say how many platter
types are in the factory (unlikely they're still making the
nice three platter 2TB drives for example).
My mental image of how it works, is if a sector is bad (minor
correctable error), it is put on the Pending queue. Yet, the
Current Pending statistic does NOT report it. As you say, on
the next Write attempt, the controller sees a sector in the
path that is dodgy. It does the write to it, then it
does a read verify. If the sector is "perfect", and passes
the test, the sector is taken off the Pending queue. If
the sector still has correctable errors or if the sector
is completely blown, it is put on reallocation, and a spare
sector is marked for usage in the table. The drive keeps the
map stored in the cache RAM, for quick access.
OK, so when does the Current Pending get used. It *seems* to
start honestly reporting Pending activity, right around
the time that the Reallocated statistic comes off 0. You
might see a burst of Current Pending after some lengthy
disk activity, followed by the Current Pending number
dropping to 0 again as it is processed. And the
sickly Reallocated climbs by roughly the amount of
Current Pending that got processed.
Some errors are High Fly errors. A percentage of drives,
have High Fly detection (DSP hooked to Write Current and
the current flow waveform tells you how high the head
is on the Z axis). That can flag a problem using
something other than a CRC error. If a High Fly error happens,
the sector can still have "good CRC" but the sector also
contains stale data. I did the forensics to see the *results*
of a High Fly on a WD Blue, while knowing the drive itself
did not sense the incident while it was happening (a
WD Blue would not have High Fly detection). A drive which
is making a High Fly error and has the detector, can process
the sector on the next rotation, put it on the Pending Queue
or in fact, just Reallocate it right on the spot. I think
the High Fly on the WD Blue on mine, is repeatable, which
means a speck of fly shit is on the platter at that location.
______X____________ fly shit plot
X_____X_____X_____X sector layout
CRCE stale OK sector status
spared stale OK after paving the drive
the CRCE one got spared out
Surface scan now "good" <cough> .
Stale sector could still be a problem
as a place to store my data (not tested).
I'm still not clear on the exact treatment of Pending materials,
and when exactly the processing of them happens, and how much
effort goes into evaluation. The processing of them, if there is
just one of them (low frequency), the write bandwidth should have
a small "glitch" in it. But in a computer, there are so many potential
causes of thruput issues, you might never notice one caused by hardware.
On 2025-10-11 21:02, Stan Brown wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
That's because there is an USB chipset in the middle. The software doesn't see the disk, it sees the chipset.
If the box is actually from WD, you should report this. It is a bug.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
Run the long SMART test, then check the disk log about it. This test actually runs in the disk firmware, doesn't involve the computer. And you can continue using the disk while it runs. However, the usb chipset can interfere.
�� For example, some boxes power down the disk at 10 minutes,
�� even if the test is running. You have in those cases to keep
�� the disk active with a script and a timer.
There are several tools to do it. I would recommend the open source smartmontools.
https://www.smartmontools.org/
https://www.smartmontools.org/wiki/Download
On 2025/10/12 14:24:14, Carlos E.R. wrote:
On 2025-10-11 21:02, Stan Brown wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
[]
My apologies; I didn't spot the word "portable" first time, when I recommended HDTune. I don't _think_ HDTune will detect errors through a
(USB I presume) portable interface: it will run, but I think the speed
will be sufficiently slow via that that any drop in speed due to
swapping out bad sectors may not be visible. Though no harm in trying!
On Sat, 10/11/2025 6:35 PM, J. P. Gilliver wrote:
On 2025/10/11 21:11:15, VanguardLH wrote:
Stan Brown <someone@example.com> wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
drive from Amazon. I'd like to do some kind of diagnostics on it to
make sure the surface is good. In Windows, File Explorer��
Properties�� Tools�� Error Checking gets an instant response that
there are no problems on the drive, so obviously that doesn't
actually check the disk surface. I went to WD's site and downloaded
their software, but when I run it I just get a message to connect a
compatible drive.
What's a good way to check the health of the disk, bad sectors
included? I have a dim memory that a regular Format (not Quick
Format) checks for bad sectors, but I could be hallucinating.
Nothing the _computer_ can do will directly tell you about surface
errors, because the electronics in the drive itself will substitute
spare sectors for any known to be bad - so anything the computer does
will get back "no bad sectors here" - until the drive runs out of spare
sectors, by which time it's time to replace it anyway.
The only thing that will show you when swapping is happening is
something that checks the _speed_ of access to all of the drive:
although all sectors will read back as OK, if the drive has to
substitute sectors from the spare pool, and has to move the heads to do
so, it will take longer for those particular sectors.
The only tool I know of that will do this is the old free version of
HDTune (and I don't know if that will work under W10, though I think it
will - Paul?). The free one is well down the download page, and many
years old. (If you can't find it, ask here, and one of us may be able to
send it to you.)
If it works, you should get a smooth curve, similar to
https://255soft.uk/temp/HDTune_1.png and
https://255soft.uk/temp/HDTune_2.png, showing the speed of access across
the disc surface - it's fastest at the start (outside of the platters).
Any dud sectors will be shown as a downward spike in the curve. But
don't worry when you get some such spikes! Because it is ancient
software, its speed test gets interrupted by any activity that Windows
does while it's running - which shows as a dip in speed at whatever
sector HDTune is checking at that moment. So you save the plot (click on
the picture of the floppy), and run it a second time and save _that_ -
then flick back and forth between the two saved images. (I find
IrfanView ideal for this, but use whatever you use to look at images, as
long as it can flick back and forth easily between two.) Any downward
spikes should be in _different places_ on the two plots, because if
HDTune was interrupted by Windows doing something, that shouldn't happen
at the same point both times. (Compare my two samples to see what I mean.) >>
You need to do this with the drive being tested actually plugged into
the motherboard, not in an external USB enclosure. (I presume it's a
SATA drive.) HDTune will ignore any partitioning - it tests the whole
drive, regardless; I don't even _think_ it has to be formatted. (Make
sure - drop-down list top left - that it's testing the right drive,
though, not your existing drive. Though if that's a real HDD, you could
always check that too! It doesn't corrupt what's on the drive, if anything.) >>
Good luck, and hope it works for you!
If anyone else knows any other way to actually check for bad sectors
that won't be fooled by the drive's electronics into not seeing any,
please share. (HDTune doesn't see bad sectors either, but its test of
the speed of access to them gives an _indication_ when swapping is
happening.)
I have a secret method for this.
Anyone who regularly uses the free version of HDTune, knows that
the constant OS activity, screws up the trace. The OS is noisy,
and the I/O noise affects the HDTUne plot.
If you prepare a Macrium Reflect Rescue CD (a WinPE environment)
and the type of installation is 32-bit (x86), you get to make
a 32 bit rescue disk. (The way to do this today, is install
a Win10 32-bit OS, install a 32-bit Macrium [must match the bitness
for the installer to work], then you can make your rescue disc.)
When you boot the Macrium Rescue disc, there is a command prompt available. You cd to your C: drive on the HDD you are benching. Navigate with
the cd, to the HDTune folder. There is one DLL missing, and the DLL
needed, is in the C: partition on the HDD you are testing. Using the
Macrium File Explorer, transfer a copy of the missing DLL, into the
folder in the Program Files on C: where the HDTune lives. Then, when
you run HDTune from the Macrium environment, you have
A QUIET OS ENVIRONMENT SUITED TO BENCHMARKING!!!
Now, run your HDTune scan, such as it is. The free version of
HDTune is most appropriate for drives 2TB or less. The paid version
likely supports any size of drive properly.
[Picture]
https://i.postimg.cc/FstVY0y2/Macriumx86-versus-Win7-for-HDTune-scanning.gif
Paul
On Sun, 10/12/2025 1:21 PM, J. P. Gilliver wrote:a
On 2025/10/12 14:24:14, Carlos E.R. wrote:
On 2025-10-11 21:02, Stan Brown wrote:
I have a (hopefully) new portable 2 TB Western Digital Elements hard
[]
My apologies; I didn't spot the word "portable" first time, when I
recommended HDTune. I don't _think_ HDTune will detect errors through
(USB I presume) portable interface: it will run, but I think the speed
will be sufficiently slow via that that any drop in speed due to
swapping out bad sectors may not be visible. Though no harm in trying!
You should still be able to bench with the HDTune.
USB works right up to the limits of the protocol. You might be
able to get to 535MB/sec when the SATA does 560MB/sec and the USB
chip is a 10Gbit/sec one (equals 1GB/sec of goodput). For benching
If you use a USB2 to SATA chip for benchmarking, that should
give on the order of 35MB/sec and will chop the top off
just about all SSDs. And make most HDDs look sad too.
HD Sentinel
Show SMART data of drives, and record history.
Free version has no testing.
Standard version ($22) only has surface testing.
Pro version ($33) has a lot more testing, some of which is destructive,
so run those before you start storing files on the drive.
Feature comparison: https://www.hdsentinel.com/store.php
GRC's Spinrite is an oldie, but still viable. It does surface testing,
and will remap bad and iffy sectors to reserve sectors. The more
remapping there is, the slower the HDD for those sectors (try to read
the bad sector, get remapped to the reserve, read the reserve).
Nothing the _computer_ can do will directly tell you about surface
errors, because the electronics in the drive itself will substitute
spare sectors for any known to be bad - so anything the computer does
will get back "no bad sectors here" - until the drive runs out of spare sectors, by which time it's time to replace it anyway.
Have you even found a portable(usb2, usb3, or usbC)Western Digital Elements Hard Drive to fail diagnosis using HDTune?
Imo, everyone is sending Stan on a goose chase.
� Copy any included WD folders on the drive to another media(or device/disk folder or usb stick)
�Format the drive as NTFS(if desired partition using Windows or 3rd party tools)
�Use the drive.
On Sun, 10/12/2025 9:24 AM, Carlos E.R. wrote:
On 2025-10-11 21:02, Stan Brown wrote:
That is a retired drive, to show an unhealthy specimen (which likely rates "GOOD"
for tools like this).
******* WD Blue 250GB SATA with high fly error on ASM2106 ********
C:\WINDOWS\system32>smartctl -a /dev/sdb
smartctl 7.5 2025-04-30 r5714 [x86_64-w64-mingw32-w10-22H2] (AppVeyor) Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
The above only provides legacy SMART information - try 'smartctl -x' for more
******* End: WD Blue 250GB SATA with high fly error on ASM2106 ********
So apparently that software knows how to do SMART passthru.
"J. P. Gilliver" <G6JPG@255soft.uk> writes:
Nothing the _computer_ can do will directly tell you about surface
So, being curious about this, has anyone seen a drive that actually
reports a non-zero number of remapped sectors? Excluding SCSI drives
since those apparently have an actual command to remap sectors.
On Mon, 10/13/2025 1:32 AM, ...winston wrote:
Have you even found a portable(usb2, usb3, or usbC)Western Digital Elements Hard Drive to fail diagnosis using HDTune?
Imo, everyone is sending Stan on a goose chase.
� Copy any included WD folders on the drive to another media(or device/disk folder or usb stick)
�Format the drive as NTFS(if desired partition using Windows or 3rd party tools)
�Use the drive.
The benchmark curve, is to find concentrated bad spots on a drive.
Bad spots are typically caused by the presence of an OS partition,
where the drive has a "wear problem" and drives begin to have issues
at the three or four year mark. Not all drives wear. The drive in
the photo, is the 57000 hour drive, and if you look at the transfer
curve, that drive is in very good shape. Similar drives to that
one have not been nearly so lucky.
I located such a problem on a WinXP drive. SMART said the drive was "Jim-Dandy", when I was using WinXP and transfers in that swath
of disk were running at 10MB/sec. After I ran a benchmark curve
and saw the actual damage, the drive was taken out of service and
retired. That was a Seagate, not a Maxtor. It might be nice to
pop that drive in the adapter and give it a spin, but I don't know
exactly where it went. It wasn't thrown out, or disassembled.
So yes, the benchmarking curve can detect situations where SMART
says a drive is OK, and anecdotal evidence ("gee this thing
seems slow") can be backed up by doing a benchmark to see
if there are any suspicious responses.
SMART works best, when defects are uniformly distributed
across the entire disk surface.
I think I may have one drive here, that SMART agrees the drive
is "Bad" :-) It has about 300 re-allocations showing. That drive
was retired, based on the rate the reallocations were growing,
but infrequent tests of the drive, aren't showing any significant
changes in drive health. I don't generally attempt to ride
hard drives into the ground. I have backups, for catastrophic
failures, like dropping a drive on the basement floor and
ruining it, would be a catastrophe I might not have predicted.
For drives that are auguring in, it is simpler to just
replace them with something a bit better. The Seagate with the
300 reallocations, it had presented some pretty weird symptoms
on a previous occasion, so describing me as nervous about
that piece of crap would be an understatement. But I can't chuck
something, unless it crosses a red line.
Some of the retired drives have a black X in marker pen on
them, but not all are marked that way. The retired ones
are a bit hard to spot.
*******
In the following picture, are three drives.
The first row, is a drive which is the sister of an identical drive.
The identical drive became defective enough, I pulled the lid off
and inside of the drive and the filter pack, was clean. It's not
clear why the sister died. Well, the drive in the top row, the
reallocations started to grow rather rapidly and while the disk
was doing reads. It's now marked on the lid as DNU and has a X on it.
The benchmark did not finish and stopped on a CRC error.
[Picture]
https://i.postimg.cc/vT0g29Sq/A-Bad-Disk-And-Two-Good-Disks.gif
The second two rows, the benchmark plots on the right, are done
under Macrium WinPE CD, and some of the spike artifacts are missing
and the plot is a little more realistic.
When you are attempting to bench C: (the one you're booted off),
that is very noisy compared to these graphs, and using the
Macrium CD is more important for evaluating C: if C: was the only
disk you had handy and had nothing else to boot from.
Summary: Stan doesn't have to do anything really.
As a result, I showed various ideas for test, which can be
used or not used as you wish. Copying files to any storage
device, and reading them back, covers cases where the operator
does not understand the setup has a fatal flaw (like the dude with
the 3TB sized array, where an address rollover occurred at 2.2TB
fill and the array was ruined). If you have any suspicion about
a drive or a RAID setup, SMART does not answer all the questions.
If you bought a "2TB USB stick for $15 from Ebay", the storage
fill test is very important for proving the fraud you received.
But if the drive does not successfully carry out a "fill-from-end-to-end"
test, you want to find out now, before you put any important
files on it.
The SMART is useful as a second opinion, when
you have other evidence (clicking, poor performance, excessive
heat) that make you want to gather some evidence or check the
drive internal log. And since the benchmark is in the same tool,
if you have a concern about a visibly slow part of a disk
(10MB/sec transfer rate over a 50-70GB wide area), then the
bench will quantify your concern.
Paul
Not questioning the method, or looking for examples of what a utility may find...only the value and effort for a new WD Elements portable disk and whether or not anyone(I, you, others) has found a new WD elements disk sufficient to warrant incapable or use(or returning for refund or replacement)
In article <5u489b3f725r.dlg@v.nguard.lh>, V@nguard.LH says...
HD SentinelHD Sentinel is excellent, and well worth the modest cost.
Show SMART data of drives, and record history.
Free version has no testing.
Standard version ($22) only has surface testing.
Pro version ($33) has a lot more testing, some of which is destructive,
so run those before you start storing files on the drive.
Feature comparison: https://www.hdsentinel.com/store.php
GRC's Spinrite is an oldie, but still viable. It does surface testing,
and will remap bad and iffy sectors to reserve sectors. The more
remapping there is, the slower the HDD for those sectors (try to read
the bad sector, get remapped to the reserve, read the reserve).
GRC recently released an updated version of Spinrite (6.1) which has guidance for SSD users. They say that an occasional "rewrite" run can
speed up an SSD significantly, though there is a cost in terms of
'wear'. A new version (7.0) is in the pipeline, but is not imminent.
I've had good success with Spinrite recovering data.
I thought, especially if only USB2 was being used, that it would (i. e. there's no point in doing it _for this purpose_); are you saying that
they _will_ still be visible, even via USB2?
On Mon, 10/13/2025 11:52 AM, ...winston wrote:
Not questioning the method, or looking for examples of what a utility may find...only the value and effort for a new WD Elements portable disk and whether or not anyone(I, you, others) has found a new WD elements disk sufficient to warrant incapable or use(or returning for refund or replacement)
Of all the hard drives I've ever owned, I only had one
infant mortality, and it was within the last two years.
It was a WD Black 1TB and the motor refused to spin
when I received it. I took it back to the computer store,
to the build-desk, and the guy there tested it, was
a bit surprised it wouldn't spin at all, and I got a swap
for it, which did work.
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk
and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or replacement)
WD Discovery features the ability to:
Manage connected external drives
Set a password and manage drive settings
Stay up-to-date with software offered by WD and WD partners
Register drive
Paul wrote:
On Mon, 10/13/2025 1:32 AM, ...winston wrote:SHIP
Have you even found a portable(usb2, usb3, or usbC)Western Digital
Elements Hard Drive to fail diagnosis using HDTune?
Imo, everyone is sending Stan on a goose chase.
�� Copy any included WD folders on the drive to another media(or
device/disk folder or usb stick)
��Format the drive as NTFS(if desired partition using Windows or 3rd
party tools)
��Use the drive.
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk
and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or replacement)
What kind of idiot company, would ship a SATA III drive in a USB2 housing ? ?All of them. It is called an external drive, most now are SSD, but have
On Mon, 13 Oct 2025 11:52:03 -0400, ...winston wrote:
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk
and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or
replacement)
I apologize: I had meant to mention the source of my suspicions, but
I forgot. Here is why I wrote "(hopefully)" before "new".
The drive is sold in a pasteboard box, and has a molded plastic shell
inside. Inside that sit, from bottom to top, the USB cable. the
owner's manual, and the drive. The USB cable was not coiled inside a
little plastic sleeve, as it was with the previous four of these
drives that I bought. As for the pasteboard box, the top has one of
those sticky plastic circles to make tampering evident, but if the
bottom ever had one it doesn't now. And the bottom is four flaps of
different sizes that fit into each other. When I took the box out of
the shipping bag, those four flaps were wide open, and only friction
was keeping the plastic shell from sliding out. Maybe that happened
during shipping, maybe not.
The drive was sold by and shipped from Amazon. But it's not uncommon
with tech products and DVDs to see in a review that Amazon shipped as
new a product that was clearly not new, most likely a return that was
just put back on the shelf. The symptoms I see with this drive are
odd, but not a real smoking gun that proves the drive is used. That's
why I wanted a recommendation for some diagnosis. Again, I'm sorry
that in composing my original query I left that out.
BTW, used space on the drive is about 1.2 MB in the form of WD
Discover. WD's website says of this software:
WD Discovery features the ability to:
Manage connected external drives
Set a password and manage drive settings
Stay up-to-date with software offered by WD and WD partners
Register drive
so I think installing it wouldn't be useful.
As I mentioned in my original, WD's diagnostic software is not
compatible with a WD Elements drive. WD's software page lists several products for download, but only WD Discovery is listed as compatible,
none of the useful ones.
If I could test the drive, that would help me decide whether to keep
it or to return it to Amazon under the principle of better safe than
sorry.
On Mon, 13 Oct 2025 11:52:03 -0400, ...winston wrote:
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk
and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or
replacement)
I apologize: I had meant to mention the source of my suspicions, but
I forgot. Here is why I wrote "(hopefully)" before "new".
The drive is sold in a pasteboard box, and has a molded plastic shell
inside. Inside that sit, from bottom to top, the USB cable. the
owner's manual, and the drive. The USB cable was not coiled inside a
little plastic sleeve, as it was with the previous four of these
drives that I bought. As for the pasteboard box, the top has one of
those sticky plastic circles to make tampering evident, but if the
bottom ever had one it doesn't now. And the bottom is four flaps of
different sizes that fit into each other. When I took the box out of
the shipping bag, those four flaps were wide open, and only friction
was keeping the plastic shell from sliding out. Maybe that happened
during shipping, maybe not.
The drive was sold by and shipped from Amazon. But it's not uncommon
with tech products and DVDs to see in a review that Amazon shipped as
new a product that was clearly not new, most likely a return that was
just put back on the shelf. The symptoms I see with this drive are
odd, but not a real smoking gun that proves the drive is used. That's
why I wanted a recommendation for some diagnosis. Again, I'm sorry
that in composing my original query I left that out.
On Mon, 13 Oct 2025 11:52:03 -0400, ...winston wrote:
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or replacement)
I apologize: I had meant to mention the source of my suspicions, but
I forgot. Here is why I wrote "(hopefully)" before "new".
The drive is sold in a pasteboard box, and has a molded plastic shell inside. Inside that sit, from bottom to top, the USB cable. the
owner's manual, and the drive. The USB cable was not coiled inside a
little plastic sleeve, as it was with the previous four of these
drives that I bought.
As for the pasteboard box, the top has one of
those sticky plastic circles to make tampering evident, but if the
bottom ever had one it doesn't now.
And the bottom is four flaps of
different sizes that fit into each other. When I took the box out of
the shipping bag, those four flaps were wide open, and only friction
was keeping the plastic shell from sliding out. Maybe that happened
during shipping, maybe not.
The drive was sold by and shipped from Amazon. But it's not uncommon
with tech products and DVDs to see in a review that Amazon shipped as
new a product that was clearly not new, most likely a return that was
just put back on the shelf. The symptoms I see with this drive are
odd, but not a real smoking gun that proves the drive is used. That's
why I wanted a recommendation for some diagnosis. Again, I'm sorry
that in composing my original query I left that out.
BTW, used space on the drive is about 1.2 MB in the form of WD
Discover. WD's website says of this software:
WD Discovery features the ability to:
Manage connected external drives
Set a password and manage drive settings
Stay up-to-date with software offered by WD and WD partners
Register drive
so I think installing it wouldn't be useful.
As I mentioned in my original, WD's diagnostic software is not
compatible with a WD Elements drive. WD's software page lists several products for download, but only WD Discovery is listed as compatible,
none of the useful ones.
If I could test the drive, that would help me decide whether to keep
it or to return it to Amazon under the principle of better safe than
sorry.
C:\WINDOWS\system32>smartctl -a /dev/sdb
On Sun, 12 Oct 2025 15:29:23 -0400, Paul wrote:
C:\WINDOWS\system32>smartctl -a /dev/sdb
Are those three "pre-fail" statuses in the attributes listing not a
sign of concern? And what about the fact that all the rest say "old
age"?
I googled and found smartctl as part of
<https://www.smartmontools.org/ >. I downloaded smartmontools as well
as the GUI, GSmartControl, which I used in preference to the command
line. As you suggested, it had no trouble finding the USB drive.
I displayed the attributes, three of which are labeled
"pre-failure" -- namely, Raw_Read_Error_Rate, Spin_Up_Time, and Reallocated_Sector_Ct, the same three as in your display. And, also
as in your display, all the rest were labeled "old age".
I'm currently running the extended test, which includes a surface
scan. ETA is 2 hours 8 minutes. I'll post the full attributes and
full results of the extended test when it finishes.
But in the meantime, what about those "pre-failure" and "old age"
notations. Do they mean that this disk is well into its useful life
period? If not, what do they mean?
On Mon, 13 Oct 2025 11:52:03 -0400, ...winston wrote:
Not questioning the method, or looking for examples of what a utility
may find...only the value and effort for a new WD Elements portable disk
and whether or not anyone(I, you, others) has found a new WD elements
disk sufficient to warrant incapable or use(or returning for refund or
replacement)
I apologize: I had meant to mention the source of my suspicions, but
I forgot. Here is why I wrote "(hopefully)" before "new".
The drive is sold in a pasteboard box, and has a molded plastic shell
inside. Inside that sit, from bottom to top, the USB cable. the
owner's manual, and the drive. The USB cable was not coiled inside a
little plastic sleeve, as it was with the previous four of these
drives that I bought. As for the pasteboard box, the top has one of
those sticky plastic circles to make tampering evident, but if the
bottom ever had one it doesn't now. And the bottom is four flaps of
different sizes that fit into each other. When I took the box out of
the shipping bag, those four flaps were wide open, and only friction
was keeping the plastic shell from sliding out. Maybe that happened
during shipping, maybe not.
The drive was sold by and shipped from Amazon. But it's not uncommon
with tech products and DVDs to see in a review that Amazon shipped as
new a product that was clearly not new, most likely a return that was
just put back on the shelf. The symptoms I see with this drive are
odd, but not a real smoking gun that proves the drive is used. That's
why I wanted a recommendation for some diagnosis. Again, I'm sorry
that in composing my original query I left that out.
If I could test the drive, that would help me decide whether to keep
it or to return it to Amazon under the principle of better safe than
sorry.
WD Discovery features the ability to:
Manage connected external drives
Set a password and manage drive settings
Stay up-to-date with software offered by WD and WD partners
Register drive
so I think installing it wouldn't be useful.
As I mentioned in my original, WD's diagnostic software is not
compatible with a WD Elements drive. WD's software page lists several products for download, but only WD Discovery is listed as compatible,
none of the useful ones.
If I could test the drive, that would help me decide whether to keep
it or to return it to Amazon under the principle of better safe than
sorry.
I'm currently running the extended test, which includes a surface
scan. ETA is 2 hours 8 minutes. I'll post the full attributes and
full results of the extended test when it finishes.
smartctl 7.5 2025-04-30 r5714 [x86_64-w64-mingw32-w10-22H2] (AppVeyor) Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: WDC WD20JDRW-11C7VS1
Serial Number: WD-WX82A458FU14
LU WWN Device Id: 5 0014ee 26c32b04b
Firmware Version: 01.01A01
User Capacity: 2,000,365,379,584 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 4800 rpm
Form Factor: 2.5 inches
TRIM Command: Available, deterministic
Device is: Not in smartctl database
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Oct 13 13:11:23 2025 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM level is: 128 (minimum power consumption without standby)
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled. Self-test execution status: ( 35) The self-test routine was interrupted
by the host with a hard or soft reset. Total time to complete Offline
data collection: ( 60) seconds.
Offline data collection
capabilities: (0x51) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported. Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 88) minutes.
SCT capabilities: (0x70b5) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
[The GUI on-screen output of the next sectction showed an
additional column, Type. Numbers 1, 3, 5 showed "pre-failure";
the rest showed "old age".]
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 100 253 051 - 0
3 Spin_Up_Time POS--K 185 185 021 - 3725
4 Start_Stop_Count -O--CK 100 100 000 - 10
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 100 253 000 - 0
9 Power_On_Hours -O--CK 100 100 000 - 2
10 Spin_Retry_Count -O--CK 100 253 000 - 0
11 Calibration_Retry_Count -O--CK 100 253 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 8
192 Power-Off_Retract_Count -O--CK 200 200 000 - 1
193 Load_Cycle_Count -O--CK 200 200 000 - 19
194 Temperature_Celsius -O---K 113 104 000 - 34
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 100 253 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 SL R/O 1 Summary SMART error log
0x02 SL R/O 5 Comprehensive SMART error log
0x03 GPL R/O 6 Ext. Comprehensive SMART error log
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x09 SL R/W 1 Selective self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x24 GPL R/O 291 Current Device Internal Status Data log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xa0-0xa7 GPL,SL VS 16 Device vendor specific log
0xa8-0xb6 GPL,SL VS 1 Device vendor specific log
0xb7 GPL,SL VS 76 Device vendor specific log
0xb9 GPL,SL VS 4 Device vendor specific log
0xbd GPL,SL VS 1 Device vendor specific log
0xc0 GPL,SL VS 1 Device vendor specific log
0xc1 GPL VS 93 Device vendor specific log
0xcf GPL VS 65535 Device vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (6 sectors)
No Errors Logged
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Interrupted (host reset) 30% 2 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
SCT Status Version: 3
SCT Version (vendor specific): 258 (0x0102)
Device State: Active (0)
Current Temperature: 35 Celsius
Power Cycle Min/Max Temperature: 21/43 Celsius
Lifetime Min/Max Temperature: 18/43 Celsius
Specified Max Operating Temperature: 22 Celsius
Under/Over Temperature Limit Count: 0/0
Vendor specific:
01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/60 Celsius
Min/Max Temperature Limit: -41/85 Celsius
Temperature History Size (Index): 128 (57)
Index Estimated Time Temperature Celsius
58 2025-10-13 11:04 27 ********
59 2025-10-13 11:05 27 ********
60 2025-10-13 11:06 28 *********
61 2025-10-13 11:07 28 *********
62 2025-10-13 11:08 ? -
63 2025-10-13 11:09 28 *********
... ..( 8 skipped). .. *********
72 2025-10-13 11:18 28 *********
73 2025-10-13 11:19 29 **********
74 2025-10-13 11:20 28 *********
75 2025-10-13 11:21 ? -
76 2025-10-13 11:22 18 -
77 2025-10-13 11:23 19 -
78 2025-10-13 11:24 19 -
79 2025-10-13 11:25 20 *
80 2025-10-13 11:26 21 **
81 2025-10-13 11:27 21 **
82 2025-10-13 11:28 22 ***
83 2025-10-13 11:29 22 ***
84 2025-10-13 11:30 22 ***
85 2025-10-13 11:31 23 ****
86 2025-10-13 11:32 23 ****
87 2025-10-13 11:33 23 ****
88 2025-10-13 11:34 24 *****
89 2025-10-13 11:35 ? -
90 2025-10-13 11:36 21 **
91 2025-10-13 11:37 21 **
92 2025-10-13 11:38 22 ***
93 2025-10-13 11:39 22 ***
94 2025-10-13 11:40 23 ****
95 2025-10-13 11:41 24 *****
96 2025-10-13 11:42 26 *******
97 2025-10-13 11:43 27 ********
98 2025-10-13 11:44 28 *********
99 2025-10-13 11:45 29 **********
100 2025-10-13 11:46 29 **********
101 2025-10-13 11:47 30 ***********
102 2025-10-13 11:48 31 ************
103 2025-10-13 11:49 32 *************
104 2025-10-13 11:50 32 *************
105 2025-10-13 11:51 33 **************
106 2025-10-13 11:52 33 **************
107 2025-10-13 11:53 35 ****************
108 2025-10-13 11:54 34 ***************
109 2025-10-13 11:55 35 ****************
110 2025-10-13 11:56 36 *****************
... ..( 2 skipped). .. *****************
113 2025-10-13 11:59 36 *****************
114 2025-10-13 12:00 37 ******************
115 2025-10-13 12:01 37 ******************
116 2025-10-13 12:02 37 ******************
117 2025-10-13 12:03 38 *******************
... ..( 3 skipped). .. *******************
121 2025-10-13 12:07 38 *******************
122 2025-10-13 12:08 39 ********************
... ..( 4 skipped). .. ********************
127 2025-10-13 12:13 39 ********************
0 2025-10-13 12:14 40 *********************
... ..( 5 skipped). .. *********************
6 2025-10-13 12:20 40 *********************
7 2025-10-13 12:21 41 **********************
... ..( 10 skipped). .. **********************
18 2025-10-13 12:32 41 **********************
19 2025-10-13 12:33 42 ***********************
... ..( 20 skipped). .. ***********************
40 2025-10-13 12:54 42 ***********************
41 2025-10-13 12:55 43 ************************
... ..( 4 skipped). .. ************************
46 2025-10-13 13:00 43 ************************
47 2025-10-13 13:01 42 ***********************
48 2025-10-13 13:02 41 **********************
49 2025-10-13 13:03 40 *********************
50 2025-10-13 13:04 39 ********************
51 2025-10-13 13:05 38 *******************
52 2025-10-13 13:06 37 ******************
53 2025-10-13 13:07 36 *****************
54 2025-10-13 13:08 35 ****************
55 2025-10-13 13:09 35 ****************
56 2025-10-13 13:10 ? -
57 2025-10-13 13:11 35 ****************
SCT Error Recovery Control command not supported
Device Statistics (GP/SMART Log 0x04) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 1 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 2 Device-to-host register FISes sent due to a COMRESET 0x000b 2 0 CRC errors within host-to-device FIS
0x000d 2 0 Non-CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC 0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC 0x8000 4 5641 Vendor specific
{
"json_format_version": [
1,
0
],
"smartctl": {
"version": [
7,
5
],
"pre_release": false,
"svn_revision": "5714",
"platform_info": "x86_64-w64-mingw32-w10-22H2",
"build_info": "(AppVeyor)",
"argv": [
"smartctl",
"--health",
"--info",
"--get=all",
"--capabilities",
"--attributes",
"--format=brief",
"--log=xerror,50,error",
"--log=xselftest,50,selftest",
"--log=selective",
"--log=directory",
"--log=scttemp",
"--log=scterc",
"--log=devstat",
"--log=sataphy",
"--json=o",
"pd1"
],
"output": [
"smartctl 7.5 2025-04-30 r5714 [x86_64-w64-mingw32-w10-22H2] (AppVeyor)",
"Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org",
"",
"=== START OF INFORMATION SECTION ===",
"Device Model: WDC WD20JDRW-11C7VS1",
"Serial Number: WD-WX82A458FU14",
"LU WWN Device Id: 5 0014ee 26c32b04b",
"Firmware Version: 01.01A01",
"User Capacity: 2,000,365,379,584 bytes [2.00 TB]",
"Sector Sizes: 512 bytes logical, 4096 bytes physical",
"Rotation Rate: 4800 rpm",
"Form Factor: 2.5 inches",
"TRIM Command: Available, deterministic",
"Device is: Not in smartctl database",
"ATA Version is: ACS-3 T13/2161-D revision 5",
"SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)",
"Local Time is: Mon Oct 13 15:17:18 2025 PDT",
"SMART support is: Available - device has SMART capability.",
"SMART support is: Enabled",
"AAM feature is: Unavailable",
"APM level is: 128 (minimum power consumption without standby)",
"Rd look-ahead is: Enabled",
"Write cache is: Enabled",
"DSN feature is: Unavailable",
"ATA Security is: Disabled, NOT FROZEN [SEC1]",
"",
"=== START OF READ SMART DATA SECTION ===",
"SMART overall-health self-assessment test result: PASSED",
"",
"General SMART Values:",
"Offline data collection status: (0x00)\tOffline data collection activity",
"\t\t\t\t\twas never started.",
"\t\t\t\t\tAuto Offline Data Collection: Disabled.",
"Self-test execution status: ( 0)\tThe previous self-test routine completed",
"\t\t\t\t\twithout error or no self-test has ever ",
"\t\t\t\t\tbeen run.",
"Total time to complete Offline ",
"data collection: \t\t( 60) seconds.",
"Offline data collection",
"capabilities: \t\t\t (0x51) SMART execute Offline immediate.",
"\t\t\t\t\tNo Auto Offline data collection support.",
"\t\t\t\t\tSuspend Offline collection upon new",
"\t\t\t\t\tcommand.",
"\t\t\t\t\tNo Offline surface scan supported.",
"\t\t\t\t\tSelf-test supported.",
"\t\t\t\t\tNo Conveyance Self-test supported.",
"\t\t\t\t\tSelective Self-test supported.",
"SMART capabilities: (0x0003)\tSaves SMART data before entering",
"\t\t\t\t\tpower-saving mode.",
"\t\t\t\t\tSupports SMART auto save timer.",
"Error logging capability: (0x01)\tError logging supported.",
"\t\t\t\t\tGeneral Purpose Logging supported.",
"Short self-test routine ",
"recommended polling time: \t ( 2) minutes.",
"Extended self-test routine",
"recommended polling time: \t ( 66) minutes.",
"SCT capabilities: \t (0x70b5)\tSCT Status supported.",
"\t\t\t\t\tSCT Feature Control supported.",
"\t\t\t\t\tSCT Data Table supported.",
"",
"SMART Attributes Data Structure revision number: 16",
"Vendor Specific SMART Attributes with Thresholds:",
"ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE",
" 1 Raw_Read_Error_Rate POSR-K 100 253 051 - 0",
" 3 Spin_Up_Time POS--K 185 185 021 - 3725",
" 4 Start_Stop_Count -O--CK 100 100 000 - 10",
" 5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0",
" 7 Seek_Error_Rate -OSR-K 200 200 000 - 0",
" 9 Power_On_Hours -O--CK 100 100 000 - 4",
" 10 Spin_Retry_Count -O--CK 100 253 000 - 0",
" 11 Calibration_Retry_Count -O--CK 100 253 000 - 0",
" 12 Power_Cycle_Count -O--CK 100 100 000 - 8",
"192 Power-Off_Retract_Count -O--CK 200 200 000 - 1",
"193 Load_Cycle_Count -O--CK 200 200 000 - 24",
"194 Temperature_Celsius -O---K 105 104 000 - 42",
"196 Reallocated_Event_Count -O--CK 200 200 000 - 0",
"197 Current_Pending_Sector -O--CK 200 200 000 - 0",
"198 Offline_Uncorrectable ----CK 100 253 000 - 0",
"199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0",
"200 Multi_Zone_Error_Rate ---R-- 200 200 000 - 0",
" ||||||_ K auto-keep",
" |||||__ C event count",
" ||||___ R error rate",
" |||____ S speed/performance",
" ||_____ O updated online",
" |______ P prefailure warning",
"",
"General Purpose Log Directory Version 1",
"SMART Log Directory Version 1 [multi-sector log support]",
"Address Access R/W Size Description",
"0x00 GPL,SL R/O 1 Log Directory",
"0x01 SL R/O 1 Summary SMART error log",
"0x02 SL R/O 5 Comprehensive SMART error log",
"0x03 GPL R/O 6 Ext. Comprehensive SMART error log",
"0x06 SL R/O 1 SMART self-test log",
"0x07 GPL R/O 1 Extended self-test log",
"0x09 SL R/W 1 Selective self-test log",
"0x10 GPL R/O 1 NCQ Command Error log",
"0x11 GPL R/O 1 SATA Phy Event Counters log",
"0x24 GPL R/O 291 Current Device Internal Status Data log",
"0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log",
"0x80-0x9f GPL,SL R/W 16 Host vendor specific log",
"0xa0-0xa7 GPL,SL VS 16 Device vendor specific log",
"0xa8-0xb6 GPL,SL VS 1 Device vendor specific log",
"0xb7 GPL,SL VS 76 Device vendor specific log",
"0xb9 GPL,SL VS 4 Device vendor specific log",
"0xbd GPL,SL VS 1 Device vendor specific log",
"0xc0 GPL,SL VS 1 Device vendor specific log",
"0xc1 GPL VS 93 Device vendor specific log",
"0xcf GPL VS 65535 Device vendor specific log",
"0xe0 GPL,SL R/W 1 SCT Command/Status",
"0xe1 GPL,SL R/W 1 SCT Data Transfer",
"",
"SMART Extended Comprehensive Error Log Version: 1 (6 sectors)",
"No Errors Logged",
"",
"SMART Extended Self-test Log Version: 1 (1 sectors)",
"Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error",
"# 1 Extended offline Completed without error 00% 4 -",
"# 2 Short offline Completed without error 00% 3 -",
"# 3 Extended offline Interrupted (host reset) 30% 2 -",
"",
"SMART Selective self-test log data structure revision number 1",
" SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS",
" 1 0 0 Not_testing",
" 2 0 0 Not_testing",
" 3 0 0 Not_testing",
" 4 0 0 Not_testing",
" 5 0 0 Not_testing",
"Selective self-test flags (0x0):",
" After scanning selected spans, do NOT read-scan remainder of disk.",
"If Selective self-test is pending on power-up, resume after 0 minute delay.",
"",
"SCT Status Version: 3",
"SCT Version (vendor specific): 258 (0x0102)",
"Device State: Active (0)",
"Current Temperature: 42 Celsius",
"Power Cycle Min/Max Temperature: 21/44 Celsius",
"Lifetime Min/Max Temperature: 18/44 Celsius",
"Specified Max Operating Temperature: 22 Celsius",
"Under/Over Temperature Limit Count: 0/0",
"Vendor specific:",
"01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
"00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
"",
"SCT Temperature History Version: 2",
"Temperature Sampling Period: 1 minute",
"Temperature Logging Interval: 1 minute",
"Min/Max recommended Temperature: 0/60 Celsius",
"Min/Max Temperature Limit: -41/85 Celsius",
"Temperature History Size (Index): 128 (54)",
"",
"Index Estimated Time Temperature Celsius",
" 55 2025-10-13 13:10 35 ****************",
" 56 2025-10-13 13:11 ? -",
" 57 2025-10-13 13:12 35 ****************",
" 58 2025-10-13 13:13 34 ***************",
" 59 2025-10-13 13:14 34 ***************",
" 60 2025-10-13 13:15 33 **************",
" ... ..( 4 skipped). .. **************",
" 65 2025-10-13 13:20 33 **************",
" 66 2025-10-13 13:21 32 *************",
" ... ..( 8 skipped). .. *************",
" 75 2025-10-13 13:30 32 *************",
" 76 2025-10-13 13:31 31 ************",
" ... ..( 7 skipped). .. ************",
" 84 2025-10-13 13:39 31 ************",
" 85 2025-10-13 13:40 32 *************",
" ... ..( 3 skipped). .. *************",
" 89 2025-10-13 13:44 32 *************",
" 90 2025-10-13 13:45 31 ************",
" 91 2025-10-13 13:46 31 ************",
" 92 2025-10-13 13:47 32 *************",
" 93 2025-10-13 13:48 33 **************",
" 94 2025-10-13 13:49 33 **************",
" 95 2025-10-13 13:50 34 ***************",
" 96 2025-10-13 13:51 35 ****************",
" 97 2025-10-13 13:52 35 ****************",
" 98 2025-10-13 13:53 36 *****************",
" 99 2025-10-13 13:54 36 *****************",
" 100 2025-10-13 13:55 37 ******************",
" 101 2025-10-13 13:56 37 ******************",
" 102 2025-10-13 13:57 37 ******************",
" 103 2025-10-13 13:58 38 *******************",
" 104 2025-10-13 13:59 38 *******************",
" 105 2025-10-13 14:00 38 *******************",
" 106 2025-10-13 14:01 39 ********************",
" ... ..( 3 skipped). .. ********************",
" 110 2025-10-13 14:05 39 ********************",
" 111 2025-10-13 14:06 40 *********************",
" ... ..( 3 skipped). .. *********************",
" 115 2025-10-13 14:10 40 *********************",
" 116 2025-10-13 14:11 41 **********************",
" ... ..( 9 skipped). .. **********************",
" 126 2025-10-13 14:21 41 **********************",
" 127 2025-10-13 14:22 42 ***********************",
" ... ..( 11 skipped). .. ***********************",
" 11 2025-10-13 14:34 42 ***********************",
" 12 2025-10-13 14:35 43 ************************",
" ... ..( 22 skipped). .. ************************",
" 35 2025-10-13 14:58 43 ************************",
" 36 2025-10-13 14:59 44 *************************",
" 37 2025-10-13 15:00 43 ************************",
" ... ..( 14 skipped). .. ************************",
" 52 2025-10-13 15:15 43 ************************",
" 53 2025-10-13 15:16 42 ***********************",
" 54 2025-10-13 15:17 42 ***********************",
"",
"SCT Error Recovery Control command not supported",
"",
"Device Statistics (GP/SMART Log 0x04) not supported",
"",
"SATA Phy Event Counters (GP Log 0x11)",
"ID Size Value Description",
"0x0001 2 0 Command failed due to ICRC error",
"0x0002 2 0 R_ERR response for data FIS",
"0x0003 2 0 R_ERR response for device-to-host data FIS",
"0x0004 2 0 R_ERR response for host-to-device data FIS",
"0x0005 2 0 R_ERR response for non-data FIS",
"0x0006 2 0 R_ERR response for device-to-host non-data FIS",
"0x0007 2 0 R_ERR response for host-to-device non-data FIS",
"0x0008 2 0 Device-to-host non-data FIS retries",
"0x0009 2 1 Transition from drive PhyRdy to drive PhyNRdy",
"0x000a 2 2 Device-to-host register FISes sent due to a COMRESET",
"0x000b 2 0 CRC errors within host-to-device FIS",
"0x000d 2 0 Non-CRC errors within host-to-device FIS",
"0x000f 2 0 R_ERR response for host-to-device data FIS, CRC",
"0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC",
"0x8000 4 13189 Vendor specific",
""
],
"exit_status": 0
},
"local_time": {
"time_t": 1760393838,
"asctime": "Mon Oct 13 15:17:18 2025 PDT"
},
"device": {
"name": "pd1",
"info_name": "pd1 [SAT]",
"type": "sat",
"protocol": "ATA"
},
"model_name": "WDC WD20JDRW-11C7VS1",
"serial_number": "WD-WX82A458FU14",
"wwn": {
"naa": 5,
"oui": 5358,
"id": 10405195851
},
"firmware_version": "01.01A01",
"user_capacity": {
"blocks": 3906963632,
"bytes": 2000365379584
},
"logical_block_size": 512,
"physical_block_size": 4096,
"rotation_rate": 4800,
"form_factor": {
"ata_value": 3,
"name": "2.5 inches"
},
"trim": {
"supported": true,
"deterministic": true,
"zeroed": false
},
"in_smartctl_database": false,
"ata_version": {
"string": "ACS-3 T13/2161-D revision 5",
"major_value": 2046,
"minor_value": 109
},
"sata_version": {
"string": "SATA 3.1",
"value": 126
},
"interface_speed": {
"max": {
"sata_value": 14,
"string": "6.0 Gb/s",
"units_per_second": 60,
"bits_per_unit": 100000000
},
"current": {
"sata_value": 3,
"string": "6.0 Gb/s",
"units_per_second": 60,
"bits_per_unit": 100000000
}
},
"smart_support": {
"available": true,
"enabled": true
},
"ata_apm": {
"enabled": true,
"level": 128,
"string": "minimum power consumption without standby",
"max_performance": false,
"min_power": true,
"with_standby": false
},
"read_lookahead": {
"enabled": true
},
"write_cache": {
"enabled": true
},
"ata_security": {
"state": 33,
"string": "Disabled, NOT FROZEN [SEC1]",
"enabled": false,
"frozen": false,
"master_password_id": 65534
},
"smart_status": {
"passed": true
},
"ata_smart_data": {
"offline_data_collection": {
"status": {
"value": 0,
"string": "was never started"
},
"completion_seconds": 60
},
"self_test": {
"status": {
"value": 0,
"string": "completed without error",
"passed": true
},
"polling_minutes": {
"short": 2,
"extended": 66
}
},
"capabilities": {
"values": [
81,
3
],
"exec_offline_immediate_supported": true,
"offline_is_aborted_upon_new_cmd": false,
"offline_surface_scan_supported": false,
"self_tests_supported": true,
"conveyance_self_test_supported": false,
"selective_self_test_supported": true,
"attribute_autosave_enabled": true,
"error_logging_supported": true,
"gp_logging_supported": true
}
},
"ata_sct_capabilities": {
"value": 28853,
"error_recovery_control_supported": false,
"feature_control_supported": true,
"data_table_supported": true
},
"ata_smart_attributes": {
"revision": 16,
"table": [
{
"id": 1,
"name": "Raw_Read_Error_Rate",
"value": 100,
"worst": 253,
"thresh": 51,
"when_failed": "",
"flags": {
"value": 47,
"string": "POSR-K ",
"prefailure": true,
"updated_online": true,
"performance": true,
"error_rate": true,
"event_count": false,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 3,
"name": "Spin_Up_Time",
"value": 185,
"worst": 185,
"thresh": 21,
"when_failed": "",
"flags": {
"value": 39,
"string": "POS--K ",
"prefailure": true,
"updated_online": true,
"performance": true,
"error_rate": false,
"event_count": false,
"auto_keep": true
},
"raw": {
"value": 3725,
"string": "3725"
}
},
{
"id": 4,
"name": "Start_Stop_Count",
"value": 100,
"worst": 100,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 10,
"string": "10"
}
},
{
"id": 5,
"name": "Reallocated_Sector_Ct",
"value": 200,
"worst": 200,
"thresh": 140,
"when_failed": "",
"flags": {
"value": 51,
"string": "PO--CK ",
"prefailure": true,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 7,
"name": "Seek_Error_Rate",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 46,
"string": "-OSR-K ",
"prefailure": false,
"updated_online": true,
"performance": true,
"error_rate": true,
"event_count": false,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 9,
"name": "Power_On_Hours",
"value": 100,
"worst": 100,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 4,
"string": "4"
}
},
{
"id": 10,
"name": "Spin_Retry_Count",
"value": 100,
"worst": 253,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 11,
"name": "Calibration_Retry_Count",
"value": 100,
"worst": 253,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 12,
"name": "Power_Cycle_Count",
"value": 100,
"worst": 100,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 8,
"string": "8"
}
},
{
"id": 192,
"name": "Power-Off_Retract_Count",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 1,
"string": "1"
}
},
{
"id": 193,
"name": "Load_Cycle_Count",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 24,
"string": "24"
}
},
{
"id": 194,
"name": "Temperature_Celsius",
"value": 105,
"worst": 104,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 34,
"string": "-O---K ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": false,
"auto_keep": true
},
"raw": {
"value": 42,
"string": "42"
}
},
{
"id": 196,
"name": "Reallocated_Event_Count",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 197,
"name": "Current_Pending_Sector",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 198,
"name": "Offline_Uncorrectable",
"value": 100,
"worst": 253,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 48,
"string": "----CK ",
"prefailure": false,
"updated_online": false,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 199,
"name": "UDMA_CRC_Error_Count",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 50,
"string": "-O--CK ",
"prefailure": false,
"updated_online": true,
"performance": false,
"error_rate": false,
"event_count": true,
"auto_keep": true
},
"raw": {
"value": 0,
"string": "0"
}
},
{
"id": 200,
"name": "Multi_Zone_Error_Rate",
"value": 200,
"worst": 200,
"thresh": 0,
"when_failed": "",
"flags": {
"value": 8,
"string": "---R-- ",
"prefailure": false,
"updated_online": false,
"performance": false,
"error_rate": true,
"event_count": false,
"auto_keep": false
},
"raw": {
"value": 0,
"string": "0"
}
}
]
},
"spare_available": {
"current_percent": 100
},
"power_on_time": {
"hours": 4
},
"power_cycle_count": 8,
"temperature": {
"current": 42,
"power_cycle_min": 21,
"power_cycle_max": 44,
"lifetime_min": 18,
"lifetime_max": 44,
"op_limit_max": 60,
"op_limit_min": 0,
"limit_min": -41,
"limit_max": 85
},
"ata_log_directory": {
"gp_dir_version": 1,
"smart_dir_version": 1,
"smart_dir_multi_sector": true,
"table": [
{
"address": 0,
"name": "Log Directory",
"read": true,
"write": false,
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 1,
"name": "Summary SMART error log",
"read": true,
"write": false,
"smart_sectors": 1
},
{
"address": 2,
"name": "Comprehensive SMART error log",
"read": true,
"write": false,
"smart_sectors": 5
},
{
"address": 3,
"name": "Ext. Comprehensive SMART error log",
"read": true,
"write": false,
"gp_sectors": 6
},
{
"address": 6,
"name": "SMART self-test log",
"read": true,
"write": false,
"smart_sectors": 1
},
{
"address": 7,
"name": "Extended self-test log",
"read": true,
"write": false,
"gp_sectors": 1
},
{
"address": 9,
"name": "Selective self-test log",
"read": true,
"write": true,
"smart_sectors": 1
},
{
"address": 16,
"name": "NCQ Command Error log",
"read": true,
"write": false,
"gp_sectors": 1
},
{
"address": 17,
"name": "SATA Phy Event Counters log",
"read": true,
"write": false,
"gp_sectors": 1
},
{
"address": 36,
"name": "Current Device Internal Status Data log",
"read": true,
"write": false,
"gp_sectors": 291
},
{
"address": 48,
"name": "IDENTIFY DEVICE data log",
"read": true,
"write": false,
"gp_sectors": 9,
"smart_sectors": 9
},
{
"address": 128,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 129,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 130,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 131,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 132,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 133,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 134,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 135,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 136,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 137,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 138,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 139,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 140,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 141,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 142,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 143,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 144,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 145,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 146,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 147,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 148,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 149,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 150,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 151,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 152,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 153,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 154,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 155,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 156,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 157,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 158,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 159,
"name": "Host vendor specific log",
"read": true,
"write": true,
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 160,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 161,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 162,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 163,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 164,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 165,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 166,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 167,
"name": "Device vendor specific log",
"gp_sectors": 16,
"smart_sectors": 16
},
{
"address": 168,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 169,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 170,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 171,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 172,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 173,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 174,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 175,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 176,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 177,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 178,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 179,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 180,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 181,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 182,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 183,
"name": "Device vendor specific log",
"gp_sectors": 76,
"smart_sectors": 76
},
{
"address": 185,
"name": "Device vendor specific log",
"gp_sectors": 4,
"smart_sectors": 4
},
{
"address": 189,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 192,
"name": "Device vendor specific log",
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 193,
"name": "Device vendor specific log",
"gp_sectors": 93
},
{
"address": 207,
"name": "Device vendor specific log",
"gp_sectors": 65535
},
{
"address": 224,
"name": "SCT Command/Status",
"read": true,
"write": true,
"gp_sectors": 1,
"smart_sectors": 1
},
{
"address": 225,
"name": "SCT Data Transfer",
"read": true,
"write": true,
"gp_sectors": 1,
"smart_sectors": 1
}
]
},
"ata_smart_error_log": {
"extended": {
"revision": 1,
"sectors": 6,
"count": 0
}
},
"ata_smart_self_test_log": {
"extended": {
"revision": 1,
"sectors": 1,
"table": [
{
"type": {
"value": 2,
"string": "Extended offline"
},
"status": {
"value": 0,
"string": "Completed without error",
"passed": true
},
"lifetime_hours": 4
},
{
"type": {
"value": 1,
"string": "Short offline"
},
"status": {
"value": 0,
"string": "Completed without error",
"passed": true
},
"lifetime_hours": 3
},
{
"type": {
"value": 2,
"string": "Extended offline"
},
"status": {
"value": 35,
"string": "Interrupted (host reset)",
"remaining_percent": 30
},
"lifetime_hours": 2
}
],
"count": 3,
"error_count_total": 0,
"error_count_outdated": 0
}
},
"ata_smart_selective_self_test_log": {
"revision": 1,
"table": [
{
"lba_min": 0,
"lba_max": 0,
"status": {
"value": 0,
"string": "Not_testing"
}
},
{
"lba_min": 0,
"lba_max": 0,
"status": {
"value": 0,
"string": "Not_testing"
}
},
{
"lba_min": 0,
"lba_max": 0,
"status": {
"value": 0,
"string": "Not_testing"
}
},
{
"lba_min": 0,
"lba_max": 0,
"status": {
"value": 0,
"string": "Not_testing"
}
},
{
"lba_min": 0,
"lba_max": 0,
"status": {
"value": 0,
"string": "Not_testing"
}
}
],
"flags": {
"value": 0,
"remainder_scan_enabled": false
},
"power_up_scan_resume_minutes": 0
},
"ata_sct_status": {
"format_version": 3,
"sct_version": 258,
"device_state": {
"value": 0,
"string": "Active"
},
"temperature": {
"current": 42,
"power_cycle_min": 21,
"power_cycle_max": 44,
"lifetime_min": 18,
"lifetime_max": 44,
"op_limit_max": 22,
"under_limit_count": 0,
"over_limit_count": 0
},
"vendor_specific": [
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"ata_sct_temperature_history": {
"version": 2,
"sampling_period_minutes": 1,
"logging_interval_minutes": 1,
"temperature": {
"op_limit_min": 0,
"op_limit_max": 60,
"limit_min": -41,
"limit_max": 85
},
"size": 128,
"index": 54,
"table": [
35,
null,
35,
34,
34,
33,
33,
33,
33,
33,
33,
32,
32,
32,
32,
32,
32,
32,
32,
32,
32,
31,
31,
31,
31,
31,
31,
31,
31,
31,
32,
32,
32,
32,
32,
31,
31,
32,
33,
33,
34,
35,
35,
36,
36,
37,
37,
37,
38,
38,
38,
39,
39,
39,
39,
39,
40,
40,
40,
40,
40,
41,
41,
41,
41,
41,
41,
41,
41,
41,
41,
41,
42,
42,
42,
42,
42,
42,
42,
42,
42,
42,
42,
42,
42,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
44,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
43,
42,
42
]
},
"sata_phy_event_counters": {
"table": [
{
"id": 1,
"name": "Command failed due to ICRC error",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 2,
"name": "R_ERR response for data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 3,
"name": "R_ERR response for device-to-host data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 4,
"name": "R_ERR response for host-to-device data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 5,
"name": "R_ERR response for non-data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 6,
"name": "R_ERR response for device-to-host non-data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 7,
"name": "R_ERR response for host-to-device non-data FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 8,
"name": "Device-to-host non-data FIS retries",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 9,
"name": "Transition from drive PhyRdy to drive PhyNRdy",
"size": 2,
"value": 1,
"overflow": false
},
{
"id": 10,
"name": "Device-to-host register FISes sent due to a COMRESET",
"size": 2,
"value": 2,
"overflow": false
},
{
"id": 11,
"name": "CRC errors within host-to-device FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 13,
"name": "Non-CRC errors within host-to-device FIS",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 15,
"name": "R_ERR response for host-to-device data FIS, CRC",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 18,
"name": "R_ERR response for host-to-device non-data FIS, CRC",
"size": 2,
"value": 0,
"overflow": false
},
{
"id": 32768,
"name": "Vendor specific",
"size": 4,
"value": 13189,
"overflow": false
}
],
"reset": false
}
}
VanguardLH wrote:
If you see pending allocations in SMART that don't reduce to zero after
a reboot then the spare sectors have been used up.
Huh, no.
Reallocation happens when writing to a bad sector. If you only read to
it, the bad sector remains active.
On Mon, 13 Oct 2025 12:14:03 -0700, Stan Brown wrote:
I'm currently running the extended test, which includes a surface
scan. ETA is 2 hours 8 minutes. I'll post the full attributes and
full results of the extended test when it finishes.
The first extended scan failed at 70% because the computer kicked
into its normal time for hibernation after idle time. I don't
understand why, since other running programs have prevented
hibernation in the past.
Anyway, I disabled hibernate based on idle
time and ran a short self test. It found no errors. I then re-ran the extended self test, and it too found no errors.
Although the GUI has separate panes for General, Attributes, Self-
Test, and so on, selecting Show Output or Save As in any of them puts
all classes of data into the output. I was able to get the output in
text form before running the Self-Test. After the Self-Test finished,
I could only get JSON form. I'm appending both/
Thank goodness for the GUI. It had no trouble displaying information,
but no matter what I tried on the command line I got an error that
boiled down to not accepting the pass-through and suggesting the
-device=TYPE option. None of the USB options on the man page worked
for me.
Before Self-Test (text)
smartctl 7.5 2025-04-30 r5714 [x86_64-w64-mingw32-w10-22H2] (AppVeyor)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org >>
=== START OF INFORMATION SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 100 253 051 - 0
3 Spin_Up_Time POS--K 185 185 021 - 3725
4 Start_Stop_Count -O--CK 100 100 000 - 10
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 100 253 000 - 0
9 Power_On_Hours -O--CK 100 100 000 - 2
10 Spin_Retry_Count -O--CK 100 253 000 - 0
11 Calibration_Retry_Count -O--CK 100 253 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 8
192 Power-Off_Retract_Count -O--CK 200 200 000 - 1
193 Load_Cycle_Count -O--CK 200 200 000 - 19
194 Temperature_Celsius -O---K 113 104 000 - 34
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 100 253 000 - 0
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. >>
SCT Status Version: 3
SCT Version (vendor specific): 258 (0x0102)
Device State: Active (0)
Current Temperature: 35 Celsius
On 10/13/2025 1:31 PM, Paul wrote:
What kind of idiot company, would ship a SATA III drive in a USB2 housing ? ?All of them.� It is called an external drive, most now are SSD, but have USB, USB2 on older drives, and USb3 on most new drives.
On Mon, 13 Oct 2025 12:14:03 -0700, Stan Brown wrote:
I'm currently running the extended test, which includes a surface
scan. ETA is 2 hours 8 minutes. I'll post the full attributes and
full results of the extended test when it finishes.
The first extended scan failed at 70% because the computer kicked
into its normal time for hibernation after idle time. I don't
understand why, since other running programs have prevented
hibernation in the past. Anyway, I disabled hibernate based on idle
time and ran a short self test. It found no errors. I then re-ran the extended self test, and it too found no errors.
Although the GUI has separate panes for General, Attributes, Self-
Test, and so on, selecting Show Output or Save As in any of them puts
all classes of data into the output. I was able to get the output in
text form before running the Self-Test. After the Self-Test finished,
I could only get JSON form. I'm appending both/
Thank goodness for the GUI. It had no trouble displaying information,
but no matter what I tried on the command line I got an error that
boiled down to not accepting the pass-through and suggesting the
-device=TYPE option. None of the USB options on the man page worked
for me.
Before Self-Test (text)
smartctl 7.5 2025-04-30 r5714 [x86_64-w64-mingw32-w10-22H2] (AppVeyor)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, www.smartmontools.org >>
=== START OF INFORMATION SECTION ===
Device Model: WDC WD20JDRW-11C7VS1
Serial Number: WD-WX82A458FU14
LU WWN Device Id: 5 0014ee 26c32b04b
Firmware Version: 01.01A01
User Capacity: 2,000,365,379,584 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 4800 rpm
Form Factor: 2.5 inches
TRIM Command: Available, deterministic
Device is: Not in smartctl database
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Oct 13 13:11:23 2025 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM level is: 128 (minimum power consumption without standby)
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled. >> Self-test execution status: ( 35) The self-test routine was interrupted
by the host with a hard or soft reset. >> Total time to complete Offline
data collection: ( 60) seconds.
Offline data collection
capabilities: (0x51) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 88) minutes.
SCT capabilities: (0x70b5) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
[The GUI on-screen output of the next sectction showed an
additional column, Type. Numbers 1, 3, 5 showed "pre-failure";
the rest showed "old age".]
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 100 253 051 - 0
3 Spin_Up_Time POS--K 185 185 021 - 3725
4 Start_Stop_Count -O--CK 100 100 000 - 10
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 100 253 000 - 0
9 Power_On_Hours -O--CK 100 100 000 - 2
10 Spin_Retry_Count -O--CK 100 253 000 - 0
11 Calibration_Retry_Count -O--CK 100 253 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 8
192 Power-Off_Retract_Count -O--CK 200 200 000 - 1
193 Load_Cycle_Count -O--CK 200 200 000 - 19
194 Temperature_Celsius -O---K 113 104 000 - 34
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 100 253 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 SL R/O 1 Summary SMART error log
0x02 SL R/O 5 Comprehensive SMART error log
0x03 GPL R/O 6 Ext. Comprehensive SMART error log
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x09 SL R/W 1 Selective self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x24 GPL R/O 291 Current Device Internal Status Data log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xa0-0xa7 GPL,SL VS 16 Device vendor specific log
0xa8-0xb6 GPL,SL VS 1 Device vendor specific log
0xb7 GPL,SL VS 76 Device vendor specific log
0xb9 GPL,SL VS 4 Device vendor specific log
0xbd GPL,SL VS 1 Device vendor specific log
0xc0 GPL,SL VS 1 Device vendor specific log
0xc1 GPL VS 93 Device vendor specific log
0xcf GPL VS 65535 Device vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (6 sectors)
No Errors Logged
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Interrupted (host reset) 30% 2 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. >>
SCT Status Version: 3
SCT Version (vendor specific): 258 (0x0102)
Device State: Active (0)
Current Temperature: 35 Celsius
Power Cycle Min/Max Temperature: 21/43 Celsius
Lifetime Min/Max Temperature: 18/43 Celsius
Specified Max Operating Temperature: 22 Celsius
Under/Over Temperature Limit Count: 0/0
Vendor specific:
01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/60 Celsius
Min/Max Temperature Limit: -41/85 Celsius
Temperature History Size (Index): 128 (57)
Index Estimated Time Temperature Celsius
58 2025-10-13 11:04 27 ********
59 2025-10-13 11:05 27 ********
60 2025-10-13 11:06 28 *********
61 2025-10-13 11:07 28 *********
62 2025-10-13 11:08 ? -
63 2025-10-13 11:09 28 *********
... ..( 8 skipped). .. *********
72 2025-10-13 11:18 28 *********
73 2025-10-13 11:19 29 **********
74 2025-10-13 11:20 28 *********
75 2025-10-13 11:21 ? -
76 2025-10-13 11:22 18 -
77 2025-10-13 11:23 19 -
78 2025-10-13 11:24 19 -
79 2025-10-13 11:25 20 *
80 2025-10-13 11:26 21 **
81 2025-10-13 11:27 21 **
82 2025-10-13 11:28 22 ***
83 2025-10-13 11:29 22 ***
84 2025-10-13 11:30 22 ***
85 2025-10-13 11:31 23 ****
86 2025-10-13 11:32 23 ****
87 2025-10-13 11:33 23 ****
88 2025-10-13 11:34 24 *****
89 2025-10-13 11:35 ? -
90 2025-10-13 11:36 21 **
91 2025-10-13 11:37 21 **
92 2025-10-13 11:38 22 ***
93 2025-10-13 11:39 22 ***
94 2025-10-13 11:40 23 ****
95 2025-10-13 11:41 24 *****
96 2025-10-13 11:42 26 *******
97 2025-10-13 11:43 27 ********
98 2025-10-13 11:44 28 *********
99 2025-10-13 11:45 29 **********
100 2025-10-13 11:46 29 **********
101 2025-10-13 11:47 30 ***********
102 2025-10-13 11:48 31 ************
103 2025-10-13 11:49 32 *************
104 2025-10-13 11:50 32 *************
105 2025-10-13 11:51 33 **************
106 2025-10-13 11:52 33 **************
107 2025-10-13 11:53 35 ****************
108 2025-10-13 11:54 34 ***************
109 2025-10-13 11:55 35 ****************
110 2025-10-13 11:56 36 *****************
... ..( 2 skipped). .. *****************
113 2025-10-13 11:59 36 *****************
114 2025-10-13 12:00 37 ******************
115 2025-10-13 12:01 37 ******************
116 2025-10-13 12:02 37 ******************
117 2025-10-13 12:03 38 *******************
... ..( 3 skipped). .. *******************
121 2025-10-13 12:07 38 *******************
122 2025-10-13 12:08 39 ********************
... ..( 4 skipped). .. ********************
127 2025-10-13 12:13 39 ********************
0 2025-10-13 12:14 40 *********************
... ..( 5 skipped). .. *********************
6 2025-10-13 12:20 40 *********************
7 2025-10-13 12:21 41 **********************
... ..( 10 skipped). .. **********************
18 2025-10-13 12:32 41 **********************
19 2025-10-13 12:33 42 ***********************
... ..( 20 skipped). .. ***********************
40 2025-10-13 12:54 42 ***********************
41 2025-10-13 12:55 43 ************************
... ..( 4 skipped). .. ************************
46 2025-10-13 13:00 43 ************************
47 2025-10-13 13:01 42 ***********************
48 2025-10-13 13:02 41 **********************
49 2025-10-13 13:03 40 *********************
50 2025-10-13 13:04 39 ********************
51 2025-10-13 13:05 38 *******************
52 2025-10-13 13:06 37 ******************
53 2025-10-13 13:07 36 *****************
54 2025-10-13 13:08 35 ****************
55 2025-10-13 13:09 35 ****************
56 2025-10-13 13:10 ? -
57 2025-10-13 13:11 35 ****************
SCT Error Recovery Control command not supported
Device Statistics (GP/SMART Log 0x04) not supported
| Sysop: | Tetrazocine |
|---|---|
| Location: | Melbourne, VIC, Australia |
| Users: | 13 |
| Nodes: | 8 (0 / 8) |
| Uptime: | 148:58:22 |
| Calls: | 177 |
| Files: | 21,502 |
| Messages: | 79,014 |
{kind=link}
{kind=link}
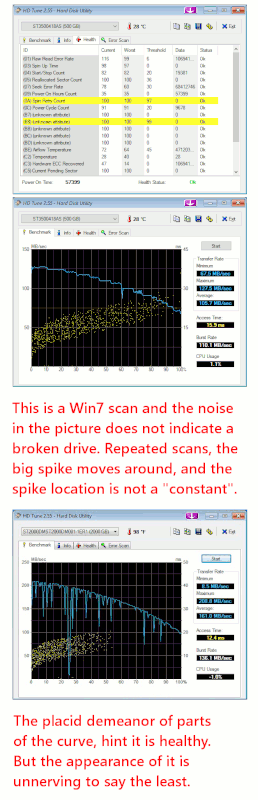{kind=link}
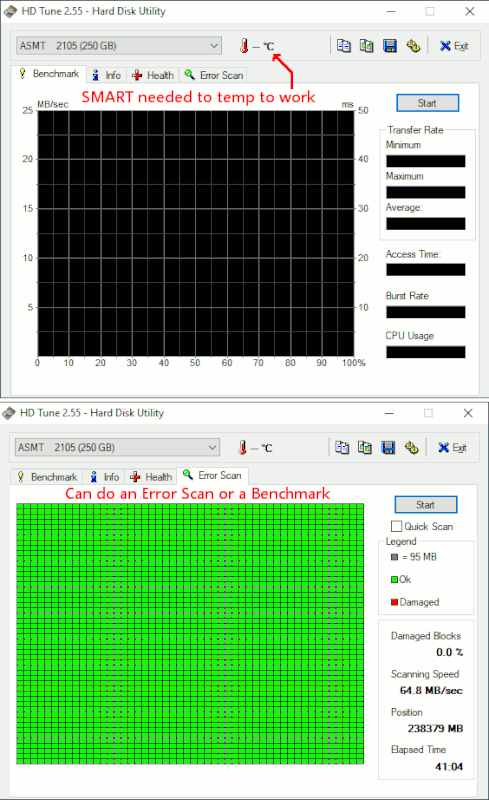{kind=link}
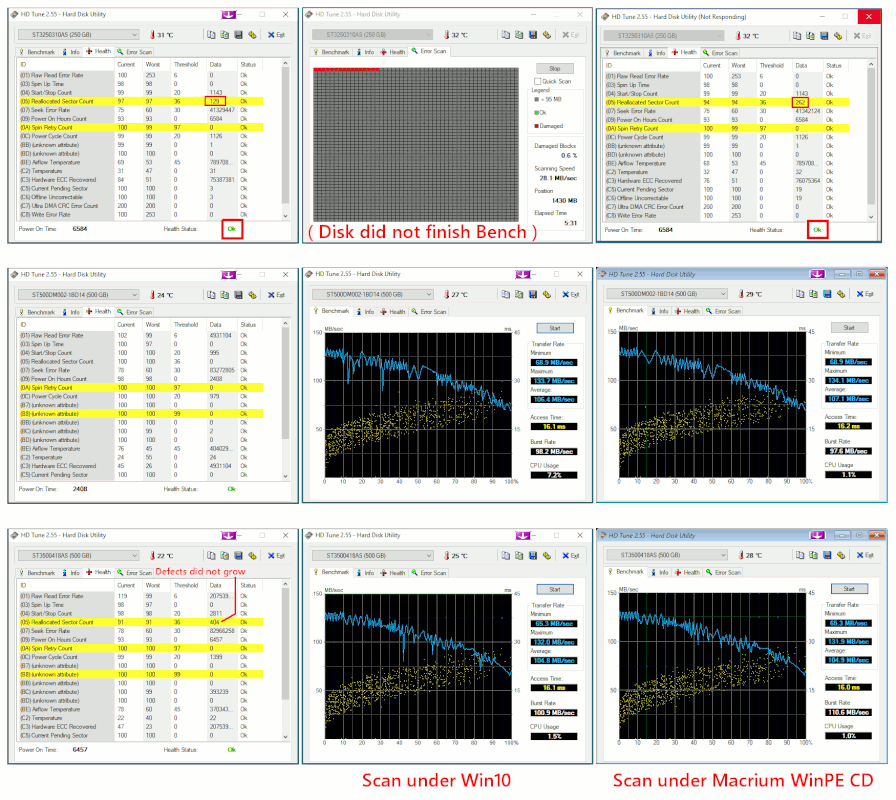{kind=link}
{kind=link}