On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before the files Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY MAINTAINING an index.
I suspect that one can set Windows to do either. But the overhead is different between the two.Because it works so poorly.
I have indeing turned off on my Windows systems.
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before the files >> Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the file is returned.
The location of the file is ONE single piece of information in the indexing system about the file.
Move the file and all you need to do is update that one piece of information.
Nothing else has changed: not it's name, not it's date modified or last opened, not it's content.
So there is no need to re-read the file.
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before the
files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to
be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an individual Byte/Bit of RAM die on you??) .... unless it still HAS the "original" file to compare the new file too??
Move the file and all you need to do is update that one piece of information.
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before the
files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to
be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an individual Byte/Bit of RAM die on you??) .... unless it still HAS the "original" file to compare the new file too??
I'm going some tech support for my brother today, and that's meant
looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in the course of that I moved the contents that had previously been
synchronized to two folders with "(Old)" added to make sure that nothing
got lost when we did it.
And I wasn't surprised when resetting his connections to his OneDrive
store and the company Sharepoint store set off a flurry of indexing. I wasn't even surprised that that took a bit of time to finish; I was re- downloading a lot of files which from the perspective of Windows, all
needed to be indexed anew.
What was completely surprising was that simply moving the those two
"Old" folders immediately caused Windows to re-index that content! I
decided to clean up the two separate "Old" stores into a single folder,
and all of a sudden, the indexing which was at 0 in Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files that
its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-indexing
isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files have finished the move.
On 10/8/2025 7:30 am, Alan wrote:
I'm going some tech support for my brother today, and that's meant
looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
This Indexing Service should have been *OPTIONAL*. The search function should work regardless of the indexing settings.
Why can't I choose a slow but more reliable method that doesn't need indexes?? :)
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM die
on me. If it did that would have zero effect on the index data needed
to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to the original File.
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before the
files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to
be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an individual Byte/Bit of RAM die on you??) .... unless it still HAS the "original" file to compare the new file too??
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM die
on me. If it did that would have zero effect on the index data needed
to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to the original File.
On 2025-10-06 10:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to
be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Two possibilities.
� a) There is a service, or daemon, that is tracking all move
operations (it must be connected to the system libraries that do the
moves). Ie, the kernel is designed to track moves and inform some higher level layer about this. Thus the indexer is told that a file moved
location.
� b) The indexer does some fast checking of the file (name, attributes, etc) and if it is the same, it assumes the file has moved. Maybe verification is delayed.
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of
information.
For that you need a system service that tracks moves and tells the
indexer. It doesn't happen automatically.
On 10/08/2025 00:30, Alan wrote:
I'm going some tech support for my brother today, and that's meant
looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in
the course of that I moved the contents that had previously been
synchronized to two folders with "(Old)" added to make sure that
nothing got lost when we did it.
And I wasn't surprised when resetting his connections to his OneDrive
store and the company Sharepoint store set off a flurry of indexing. I
wasn't even surprised that that took a bit of time to finish; I was
re- downloading a lot of files which from the perspective of Windows,
all needed to be indexed anew.
What was completely surprising was that simply moving the those two
"Old" folders immediately caused Windows to re-index that content! I
decided to clean up the two separate "Old" stores into a single
folder, and all of a sudden, the indexing which was at 0 in
Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files that
its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-indexing
isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files
have finished the move.
Surely most people just turn indexing off.
It's pretty useless anyway.
But you can leave it on if you have an SSD without it causing too muchOr you could use a decent operating system.
of a problem.
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM die
on me. If it did that would have zero effect on the index data needed
to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to the original File.
On 06/10/2025 10:54, Daniel70 wrote:
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it
to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still HAS
the "original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM
die on me. If it did that would have zero effect on the index data
needed to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to
the original File.
No .... it would mean that the 'moved' file *IS* corrupted. File
indexing systems CANNOT record and search for data corruption.
On 2025-10-06 07:45, Brian Gregory wrote:
On 10/08/2025 00:30, Alan wrote:
I'm going some tech support for my brother today, and that's meant
looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in
the course of that I moved the contents that had previously been
synchronized to two folders with "(Old)" added to make sure that
nothing got lost when we did it.
And I wasn't surprised when resetting his connections to his OneDrive
store and the company Sharepoint store set off a flurry of indexing.
I wasn't even surprised that that took a bit of time to finish; I was
re- downloading a lot of files which from the perspective of Windows,
all needed to be indexed anew.
What was completely surprising was that simply moving the those two
"Old" folders immediately caused Windows to re-index that content! I
decided to clean up the two separate "Old" stores into a single
folder, and all of a sudden, the indexing which was at 0 in
Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files that
its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-
indexing isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files
have finished the move.
Surely most people just turn indexing off.
Not on macOS.
It's pretty useless anyway.
Just on Windows.
But you can leave it on if you have an SSD without it causing too muchOr you could use a decent operating system.
of a problem.
On 06/10/2025 17:13, Alan wrote:Why wouldn't you WANT TO BE ABLE TO when necessary?
On 2025-10-06 07:45, Brian Gregory wrote:
On 10/08/2025 00:30, Alan wrote:
I'm going some tech support for my brother today, and that's meant
looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in
the course of that I moved the contents that had previously been
synchronized to two folders with "(Old)" added to make sure that
nothing got lost when we did it.
And I wasn't surprised when resetting his connections to his
OneDrive store and the company Sharepoint store set off a flurry of
indexing. I wasn't even surprised that that took a bit of time to
finish; I was re- downloading a lot of files which from the
perspective of Windows, all needed to be indexed anew.
What was completely surprising was that simply moving the those two
"Old" folders immediately caused Windows to re-index that content! I
decided to clean up the two separate "Old" stores into a single
folder, and all of a sudden, the indexing which was at 0 in
Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files
that its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-
indexing isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files
have finished the move.
Surely most people just turn indexing off.
Not on macOS.
It's pretty useless anyway.
Just on Windows.
But you can leave it on if you have an SSD without it causing tooOr you could use a decent operating system.
much of a problem.
If you'll buy me new Linux or Mac versions of all my software I'd be
glad to try a better OS.
What kind of brain dead person needs to search everything on their hard drive for that one document then mentioned that one thing that they miraculously remember the name of while they mysteriously completely
forget when or where on their computer it was mentioned, yet somehow
they managed to remember it was on their computer they saw it rather
than on TV or in the Newspaper.
On 06/10/2025 10:54, Daniel70 wrote:
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it
to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still HAS
the "original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM
die on me. If it did that would have zero effect on the index data
needed to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to
the original File.
You're being silly.
It's not the job of software to continuously expend lots of effort just
so that it can carry on as if nothing has happened if and when at some
point in the future the hardware starts to fail.
On 2025-10-06 01:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to
be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Oh dear GOD!
You cannot be this ignorant.
When you "move" a file from one directory to another on a partition, the actual data of the file IS NOT TOUCHED.
The individual bits of the file stay in exactly the same place.
All that's changed is the file system's record of which directory the
file should be displayed as being in.
Do you know what a "hard link" is?
On 2025-10-06 05:17, Carlos E.R. wrote:
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of
information.
For that you need a system service that tracks moves and tells the
indexer. It doesn't happen automatically.
And why would that be at all difficult?
You have a journaled file system, so all you need is a process that
checks for events in the journal that actually DO mean that there is a
new file that's been created or that a file has been changed.
Those events require that a file get re-indexed. Moving a file within
the same volume does NOT.
That process on macOS is called "fseventsd"
Look it up.
On 2025-10-06 16:59, Brian Gregory wrote:
On 06/10/2025 10:54, Daniel70 wrote:
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it >>>>>>> to be re-read?
Alan> Did its content magically change just because you moved it? >>>>>>> Alan> No.
This is the difference between indexing on demand versus
CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the >>>>>> file is returned.
The location of the file is ONE single piece of information in the >>>>>> indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or >>>>>> last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still
HAS the "original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM
die on me. If it did that would have zero effect on the index data
needed to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to
the original File.
You're being silly.
It's not the job of software to continuously expend lots of effort
just so that it can carry on as if nothing has happened if and when at
some point in the future the hardware starts to fail.
Actually, it is.
There are advanced filesystems that certify that files do not change "accidentally".
On 2025-10-06 17:58, Alan wrote:
On 2025-10-06 01:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Oh dear GOD!
You cannot be this ignorant.
When you "move" a file from one directory to another on a partition,
the actual data of the file IS NOT TOUCHED.
The individual bits of the file stay in exactly the same place.
All that's changed is the file system's record of which directory the
file should be displayed as being in.
Do you know what a "hard link" is?
And how does the indexer know that this has happened?
Oh, Windows supports hardlinks only on NTFS. Not on FAT or exFAT or ReFS.Yeah... ...I know.
On 2025-10-06 18:12, Alan wrote:
On 2025-10-06 05:17, Carlos E.R. wrote:
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of
information.
For that you need a system service that tracks moves and tells the
indexer. It doesn't happen automatically.
And why would that be at all difficult?
You have a journaled file system, so all you need is a process that
checks for events in the journal that actually DO mean that there is a
new file that's been created or that a file has been changed.
Those events require that a file get re-indexed. Moving a file within
the same volume does NOT.
That process on macOS is called "fseventsd"
Look it up.
Not going to look it up, I don't do macs. I'll accept your word.
Does Windows do it?
On 2025-10-06 13:44, Carlos E.R. wrote:
On 2025-10-06 17:58, Alan wrote:
On 2025-10-06 01:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it
to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still HAS
the "original" file to compare the new file too??
Oh dear GOD!
You cannot be this ignorant.
When you "move" a file from one directory to another on a partition,
the actual data of the file IS NOT TOUCHED.
The individual bits of the file stay in exactly the same place.
All that's changed is the file system's record of which directory the
file should be displayed as being in.
Do you know what a "hard link" is?
And how does the indexer know that this has happened?
How does the indexer know ANYTHING has happened?
How about, it checks the file system journal.
A "new file" entry: index that file.
A "file modified" entriy: index that file.
A "file moved" entry: modify the index to show the new location.
Yeah... ...I know.
Oh, Windows supports hardlinks only on NTFS. Not on FAT or exFAT or ReFS.
On 2025-10-06 13:47, Carlos E.R. wrote:
On 2025-10-06 18:12, Alan wrote:
On 2025-10-06 05:17, Carlos E.R. wrote:
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of
information.
For that you need a system service that tracks moves and tells the
indexer. It doesn't happen automatically.
And why would that be at all difficult?
You have a journaled file system, so all you need is a process that
checks for events in the journal that actually DO mean that there is
a new file that's been created or that a file has been changed.
Those events require that a file get re-indexed. Moving a file within
the same volume does NOT.
That process on macOS is called "fseventsd"
Look it up.
Not going to look it up, I don't do macs. I'll accept your word.
Does Windows do it?
Apparently not.
Which is why I wrote subject I did:
"It is stunning when you see how badly Windows operates: indexing"
On 2025-10-06 22:56, Alan wrote:
On 2025-10-06 13:44, Carlos E.R. wrote:
On 2025-10-06 17:58, Alan wrote:
On 2025-10-06 01:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it >>>>>>> to be re-read?
Alan> Did its content magically change just because you moved it? >>>>>>> Alan> No.
This is the difference between indexing on demand versus
CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the >>>>>> file is returned.
The location of the file is ONE single piece of information in the >>>>>> indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or >>>>>> last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still
HAS the "original" file to compare the new file too??
Oh dear GOD!
You cannot be this ignorant.
When you "move" a file from one directory to another on a partition,
the actual data of the file IS NOT TOUCHED.
The individual bits of the file stay in exactly the same place.
All that's changed is the file system's record of which directory
the file should be displayed as being in.
Do you know what a "hard link" is?
And how does the indexer know that this has happened?
How does the indexer know ANYTHING has happened?
How about, it checks the file system journal.
Can it?
I have my doubts. In Linux, it is in kernelspace. I don't know if it can
be queried.
Because Windows absolutely SUCKS at this.
A "new file" entry: index that file.
A "file modified" entriy: index that file.
A "file moved" entry: modify the index to show the new location.
Yeah... ...I know.
Oh, Windows supports hardlinks only on NTFS. Not on FAT or exFAT or
ReFS.
Well, this thread is posted on two windows groups.
On 10/08/2025 00:30, Alan wrote:
I'm going some tech support for my brother today, and that's meant looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in the course of that I moved the contents that had previously been synchronized to two folders with "(Old)" added to make sure that nothing got lost when we did it.
And I wasn't surprised when resetting his connections to his OneDrive store and the company Sharepoint store set off a flurry of indexing. I wasn't even surprised that that took a bit of time to finish; I was re- downloading a lot of files which from the perspective of Windows, all needed to be indexed anew.
What was completely surprising was that simply moving the those two "Old" folders immediately caused Windows to re-index that content! I decided to clean up the two separate "Old" stores into a single folder, and all of a sudden, the indexing which was at 0 in Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files that its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-indexing isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files have finished the move.
Surely most people just turn indexing off.
It's pretty useless anyway.
But you can leave it on if you have an SSD without it causing too much of a problem.
On 2025-10-06 23:12, Alan wrote:A move to another volume is never really a move, now is it?
On 2025-10-06 13:47, Carlos E.R. wrote:
On 2025-10-06 18:12, Alan wrote:
On 2025-10-06 05:17, Carlos E.R. wrote:
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of
information.
For that you need a system service that tracks moves and tells the
indexer. It doesn't happen automatically.
And why would that be at all difficult?
You have a journaled file system, so all you need is a process that
checks for events in the journal that actually DO mean that there is
a new file that's been created or that a file has been changed.
Those events require that a file get re-indexed. Moving a file
within the same volume does NOT.
That process on macOS is called "fseventsd"
Look it up.
Not going to look it up, I don't do macs. I'll accept your word.
Does Windows do it?
Apparently not.
Which is why I wrote subject I did:
"It is stunning when you see how badly Windows operates: indexing"
Well, I know that I have moved in the past huge content in Linux and
seen several content indexers re-index them. I would have to test again noticing if it was the same partition.
On Mon, 10/6/2025 10:45 AM, Brian Gregory wrote:
On 10/08/2025 00:30, Alan wrote:
I'm going some tech support for my brother today, and that's meant looking "under the hood" of his Windows 10 machine.
And it is astounding how poorly Windows handles indexing content.
I had to uninstall OneDrive and set it up again from scratch and in the course of that I moved the contents that had previously been synchronized to two folders with "(Old)" added to make sure that nothing got lost when we did it.
And I wasn't surprised when resetting his connections to his OneDrive store and the company Sharepoint store set off a flurry of indexing. I wasn't even surprised that that took a bit of time to finish; I was re- downloading a lot of files which from the perspective of Windows, all needed to be indexed anew.
What was completely surprising was that simply moving the those two "Old" folders immediately caused Windows to re-index that content! I decided to clean up the two separate "Old" stores into a single folder, and all of a sudden, the indexing which was at 0 in Settings:Search:Searching Windows
Windows isn't smart enough to recognize that these are all files that its already indexed and they're now just in a new location!
About 80,000 files were move about 30 minutes ago, and the re-indexing isn't even 25% done!
If I do a similar thing on macOS, it's done almost before the files have finished the move.
Surely most people just turn indexing off.
It's pretty useless anyway.
But you can leave it on if you have an SSD without it causing too much of a problem.
How the Indexer works, is going to depend on how the Change Journal works. The Indexer is not a 60 line program and a "tight ball of code". There
are three running processes in Task Manager for the operation of it. It's rather big, as packaging goes. The processes even run with different priorities (one runs at a lower priority setting than the others and
gets trashed and restarted every once in a while).
*******
Doing operations on the file system, developers are able to get different levels of performance. The NFI.exe utility from Microsoft, is my "go to" utility when I must know what is in a partition. It was written in the
year 2003, and badly needs an update to be written (in particular, the $FILE_NAME entry, the string stored in there needs to be printed on
the screen and that is missing information). Files which have multiple $FILE_NAME, are hardlinked files. Notice here, how I am able to find
the Windows 11 Search Indexer inverted index file. It is stored on the
file system as Filenum 23838 and is lightly fragmented.
.\nfi C: > nfi-C-out.txt # And, 145 seconds later... 210MB listing 2,771,720 lines
File 23838
\ProgramData\Microsoft\Search\Data\Applications\Windows\Windows.db
$STANDARD_INFORMATION (resident)
$FILE_NAME (resident)
$DATA (nonresident)
logical sectors 33709448-33712863 (0x2025d88-0x2026adf)
... (30 fragments total) (early search Index had hundreds of fragments)
logical sectors 91984216-91984239 (0x57b9158-0x57b916f)
The Indexer file is 2.35MB in size, as the Indexer in this machine is not configured
to index anything..
Now compare that to a VoidTool Everything.exe attempt to list a file system. Everything.exe does an "initial index" at machine startup, and you can tap into
that by using the utiity without all of its baggage ("one-shot" utility usage).
Now, it's not always this fast, but this is a good demo.
.\Everything.exe -create-filelist every_c.txt "C:" # Examine the text file, to see the metadata
# they keep in there. This emulates the initial
# indexing process. You cannot list the WsL1 tree
# files this way, they are ignored. Neither would
# it pretend to access System Volume Information files.
# There are safety reasons for staying out of there.
7 seconds, 56,985,788 bytes output 360,000 lines or so. Entries for five files shown.
Filename, Size, Date Modified, Date Created, Attributes
"C:\Users\paul\Downloads\Windows-universal-samples-main--includes-OCR-sample.zip",28899211,133659001969022138,134034795503869343,32
"C:\Users\paul\Downloads\windows10.0-kb5034232-x64_SafeOS-WinRE-example.cab",7530358,133696434360300569,134034795502291984,32
"C:\Users\paul\Downloads\Windows10Upgrade9252.exe",3343496,133195821885381788,134034795502453969,32
"C:\Users\paul\Downloads\Windows11Upgrade_EN.zip",409341,132937705786434792,134034795502762944,32
"C:\Users\paul\Downloads\Windows6.1-KB3004394-v2-x64.msu",2442957,132894276659630869,134034795501816348,32
That code then, has different objectives, but the code is 20x faster in the example.
The very first version of the Voidtools work, did that job in *2* seconds, but back then
all you got was a filename absolute path (no numbers on the end).
The Content Indexing that Microsoft does, is a mondo bloat thing to do.
It's orders of magnitude slower, and it takes all day to Content Index my "NAS collection".
The Content Indexer is recommended to not be indexing more than 1 million files.
That's what Microsoft specs as a practical limit. You can drive it harder than that, but expect some aspect to be slower.
Summary: No one in their right mind uses the search box in File Explorer.
How many times has it missed stuff ? You decide.
But there are signs that maintainers still fiddle around with
the implementation. In Win10 it uses Windows.edb "Jet Blue" database.
In Win11 it uses Windows.db SQLite3 database. This makes no different
at the user level (and isn't this why we write code???).
I think if we had a Change Journal expert here, we could get an answer
on how file moves are encoded, how many entries such an activity would
span, and whether an architecture would allow optimization for it.
It's the same when a naive person watches the miserably slow file deletion.
The person would say "hey, why not stop the computer for a second,
total up all the changes to the $MFT and just blast them in as a huge edit".
and that causes a huge explanation of why we can't/won't be doing that.
If that was even remotely possible, we'd have done it by now. Or at least,
there would be a credible explanation of how we could do it.
Paul
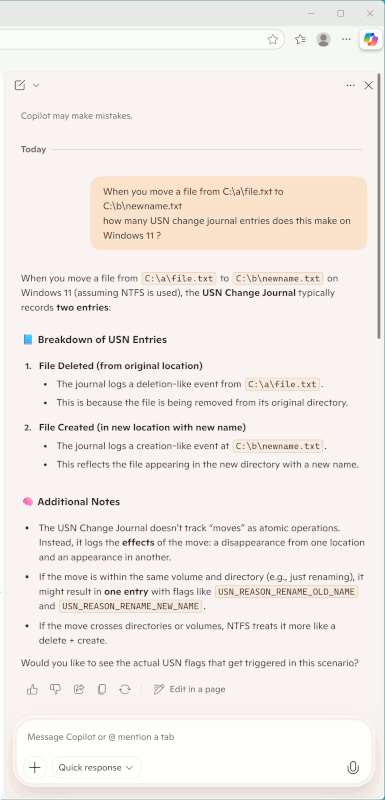
Paul, you're the idiot that claimed moving a file resulted in a "deletefile" in the USN Journal...
...and you were spectacularly wrong.
On Mon, 10/6/2025 8:27 PM, Alan wrote:
Paul, you're the idiot that claimed moving a file resulted in a "deletefile" in the USN Journal...
...and you were spectacularly wrong.
Here is some CoPilot feedback.
[Picture]
https://i.postimg.cc/J4qxv3Wn/Co-Pilot-Comment-On-USN.gif
[Picture]
https://i.postimg.cc/6pV8Yzs0/USN-move-testcase.gif
Paul
On 6/10/2025 11:22 pm, Carlos E.R. wrote:
On 2025-10-06 10:23, Daniel70 wrote:So are you, Carlos, suggesting that, at the time of the move/copy, the
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Two possibilities.
�� a) There is a service, or daemon, that is tracking all move
operations (it must be connected to the system libraries that do the
moves). Ie, the kernel is designed to track moves and inform some
higher level layer about this. Thus the indexer is told that a file
moved location.
�� b) The indexer does some fast checking of the file (name,
attributes, etc) and if it is the same, it assumes the file has moved.
Maybe verification is delayed.
OS does not check that what ends up at the new/final location is the
same as what was in the old/original location??
If that *IS* the case, I hope no-one EVER does a Defrag!! EVER!!
Sorry! WHAT?? A file THAT I'VE DONE NOTHING TO might change!
Really??
WHEN??
WHY??Hard (and floppy) discs - areas magnetised lose or gain difference from adjacent ones. SSDs - charge leaks away (or in). Optical discs - the dye
At some indeterminate time in the future??
SURE!!Indeed!
On 2025-10-08 11:30, Daniel70 wrote:
So are you, Carlos, suggesting that, at the time of the move/copy, the
OS does not check that what ends up at the new/final location is the
same as what was in the old/original location??
If it is an move via hardlink operation, then as the data sectors are
not touched, only the metadata, the data is guaranteed to be the same.
If it is copy-and-delete operation, the system does not do an automated
check that what is actually written is the same data.
However, the userland program doing the operation can do a verify before
delete.
If that *IS* the case, I hope no-one EVER does a Defrag!! EVER!!
Not related, either. The application doing the defrag can do a verify.
In Linux, there are filesystems that store a checksum of files in the metadata, so that integrity can be verified. It is not the default.
Alan, would you be satisfied if I had said/asked what happens when a
File is 'COPIED' rather than 'MOVED'??
Would I end up with TWO copies of the File on my HD??
If I then deleted the ORIGINAL file, how do I *KNOW* that the remaining
file is the same as the ORIGINAL file??You don't, unless you invoked the verify option (or it is on by default)
Surely this can't be so .... or has Copilot just not completed the process??
On 7/10/2025 1:59 am, Brian Gregory wrote:
On 06/10/2025 10:54, Daniel70 wrote:Correct. So the OP COULD have checked/compared the ORIGINAL file with
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it >>>>>>> to be re-read?
Alan> Did its content magically change just because you moved it? >>>>>>> Alan> No.
This is the difference between indexing on demand versus
CONTINUOUSLY
MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the >>>>>> file is returned.
The location of the file is ONE single piece of information in the >>>>>> indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or >>>>>> last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still
HAS the "original" file to compare the new file too??
As it happens I have never *noticed* an individual Byte/Bit of RAM
die on me. If it did that would have zero effect on the index data
needed to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different to
the original File.
You're being silly.
It's not the job of software to continuously expend lots of effort
just so that it can carry on as if nothing has happened if and when at
some point in the future the hardware starts to fail.
the RELOCATED to ensure they are IDENTICAL ..... but, somehow, I don't
think the SOFTWARE/OS does that check.
On 7/10/2025 3:33 am, Alan wrote:
On 2025-10-06 09:28, MikeS wrote:
On 06/10/2025 10:54, Daniel70 wrote:
On 6/10/2025 7:56 pm, MikeS wrote:
On 06/10/2025 09:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote: Alan>>> If I do a similar
thing on macOS, it's done almost before the files Alan>>>
have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its
content... Alan> ...why would simply moving it to a new
location require it to be re-read? Alan> Did its content
magically change just because you moved it? Alan> No.
This is the difference between indexing on demand versus
�CONTINUOUSLY MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata
and content.
When a search happens, the INDEX gets searched the location
of the file is returned.
The location of the file is ONE single piece of information
in the indexing system about the file.
Move the file and all you need to do is update that one
piece of information.
Nothing else has changed: not it's name, not it's date
modified or last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the
"new" "moved" file is *EXACTLY* the same as the original file
(never had an individual Byte/Bit of RAM die on you??) ....
unless it still HAS the "original" file to compare the new
file too??
As it happens I have never *noticed* an individual Byte/Bit of
RAM die on me. If it did that would have zero effect on the
index data needed to search for the file.
Sure .... but it would mean that the 'moved' file *IS* different
to the original File.
No .... it would mean that the 'moved' file *IS* corrupted.
AH!! So MikeS doesn't consider a moved but corrupted file is different
to the original file. Good to know!!
On 6/10/2025 11:22 pm, Carlos E.R. wrote:
On 2025-10-06 10:23, Daniel70 wrote:So are you, Carlos, suggesting that, at the time of the move/copy, the
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Two possibilities.
�� a) There is a service, or daemon, that is tracking all move
operations (it must be connected to the system libraries that do the
moves). Ie, the kernel is designed to track moves and inform some
higher level layer about this. Thus the indexer is told that a file
moved location.
�� b) The indexer does some fast checking of the file (name,
attributes, etc) and if it is the same, it assumes the file has moved.
Maybe verification is delayed.
OS does not check that what ends up at the new/final location is the
same as what was in the old/original location??
If that *IS* the case, I hope no-one EVER does a Defrag!! EVER!!
On 2025-10-08 11:30, Daniel70 wrote:
On 6/10/2025 11:22 pm, Carlos E.R. wrote:
On 2025-10-06 10:23, Daniel70 wrote:So are you, Carlos, suggesting that, at the time of the move/copy, the
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before >>>>>> the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it
to be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and
content.
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had
an individual Byte/Bit of RAM die on you??) .... unless it still HAS
the "original" file to compare the new file too??
Two possibilities.
�� a) There is a service, or daemon, that is tracking all move
operations (it must be connected to the system libraries that do the
moves). Ie, the kernel is designed to track moves and inform some
higher level layer about this. Thus the indexer is told that a file
moved location.
�� b) The indexer does some fast checking of the file (name,
attributes, etc) and if it is the same, it assumes the file has
moved. Maybe verification is delayed.
OS does not check that what ends up at the new/final location is the
same as what was in the old/original location??
If it is an move via hardlink operation, then as the data sectors are
not touched, only the metadata, the data is guaranteed to be the same.
If it is copy-and-delete operation, the system does not do an automated check that what is actually written is the same data.
However, the userland program doing the operation can do a verify before delete.
If that *IS* the case, I hope no-one EVER does a Defrag!! EVER!!
Not related, either. The application doing the defrag can do a verify.
In Linux, there are filesystems that store a checksum of files in the metadata, so that integrity can be verified. It is not the default.
On 2025/10/8 10:48:19, Carlos E.R. wrote:
On 2025-10-08 11:30, Daniel70 wrote:
[]
So are you, Carlos, suggesting that, at the time of the move/copy, the
OS does not check that what ends up at the new/final location is the
same as what was in the old/original location??
If it is an move via hardlink operation, then as the data sectors are
not touched, only the metadata, the data is guaranteed to be the same.
(Hmm, arguably that's not a move, though it looks like one to the user -
a "move" to another place on the same partition usually only involves changing pointers.)>
If it is copy-and-delete operation, the system does not do an automated
check that what is actually written is the same data.
Indeed. The _checksums_ (or more complex equivalents) may well be recalculated (possibly at the hardware level).>
However, the userland program doing the operation can do a verify before
delete.
Indeed. A lot of copy/move commands have a verify _option_; I don't know
if any have it on by default.>
Well, it _is_ related: a defrag _is_ a copy-and-delete (usually many of them). How many defrags do verify by default, I do not know.>
If that *IS* the case, I hope no-one EVER does a Defrag!! EVER!!
Not related, either. The application doing the defrag can do a verify.
In Linux, there are filesystems that store a checksum of files in theA lot of (all modern, even floppy?) systems - hard disc drives, probably
metadata, so that integrity can be verified. It is not the default.
SSDs - do that at a low level anyway, as their error-correction mechanism.>
On 7/10/2025 2:58 am, Alan wrote:
On 2025-10-06 01:23, Daniel70 wrote:
On 6/10/2025 3:16 pm, Alan wrote:
On 2025-10-05 19:46, Lars Poulsen wrote:
Alan <nuh-uh@nope.com> wrote:
Alan>>> If I do a similar thing on macOS, it's done almost before
the files
Alan>>> have finished the move
On 2025-10-01 13:19, Carlos E.R. wrote:Carlos>> Not if it does content indexing.
Alan> If a file has already BEEN indexed for its content...
Alan> ...why would simply moving it to a new location require it to >>>>> be re-read?
Alan> Did its content magically change just because you moved it?
Alan> No.
This is the difference between indexing on demand versus CONTINUOUSLY >>>>> MAINTAINING an index.
I'm sorry, but you're wrong.
You index a file so that you can find it based on metadata and content. >>>>
When a search happens, the INDEX gets searched the location of the
file is returned.
The location of the file is ONE single piece of information in the
indexing system about the file.
Move the file and all you need to do is update that one piece of
information.
Nothing else has changed: not it's name, not it's date modified or
last opened, not it's content.
So there is no need to re-read the file.
How is your system supposed to know that the contents of the "new"
"moved" file is *EXACTLY* the same as the original file (never had an
individual Byte/Bit of RAM die on you??) .... unless it still HAS the
"original" file to compare the new file too??
Oh dear GOD!
You cannot be this ignorant.
When you "move" a file from one directory to another on a partition,
the actual data of the file IS NOT TOUCHED.
The individual bits of the file stay in exactly the same place.
All that's changed is the file system's record of which directory the
file should be displayed as being in.
Do you know what a "hard link" is?
Alan, would you be satisfied if I had said/asked what happens when a
File is 'COPIED' rather than 'MOVED'??
Would I end up with TWO copies of the File on my HD??
If I then deleted the ORIGINAL file, how do I *KNOW* that the remaining
file is the same as the ORIGINAL file??
On 7/10/2025 10:55 am, Alan wrote:
On 2025-10-06 14:25, Carlos E.R. wrote:
On 2025-10-06 23:12, Alan wrote:A move to another volume is never really a move, now is it?
On 2025-10-06 13:47, Carlos E.R. wrote:
On 2025-10-06 18:12, Alan wrote:
On 2025-10-06 05:17, Carlos E.R. wrote:
On 2025-10-06 06:16, Alan wrote:
Move the file and all you need to do is update that one piece of >>>>>>>> information.
For that you need a system service that tracks moves and tells
the indexer. It doesn't happen automatically.
And why would that be at all difficult?
You have a journaled file system, so all you need is a process
that checks for events in the journal that actually DO mean that
there is a new file that's been created or that a file has been
changed.
Those events require that a file get re-indexed. Moving a file
within the same volume does NOT.
That process on macOS is called "fseventsd"
Look it up.
Not going to look it up, I don't do macs. I'll accept your word.
Does Windows do it?
Apparently not.
Which is why I wrote subject I did:
"It is stunning when you see how badly Windows operates: indexing"
Well, I know that I have moved in the past huge content in Linux and
seen several content indexers re-index them. I would have to test
again noticing if it was the same partition.
The OS can make the end result appear to be the SAME as a move, but if
you want the files on a different volume, then the data in those files
will have to be WRITTEN to that new volume and of course the indexing
for that volume will have no entries for those files...
...because from the context of that new volume?
...THEY WILL BE NEW FILES.
So when DO those files that YOU have WRITTEN to that new volume actually
get listed in the content of that new volume??
And when do they get deleted from the original volume .... and de-
Indexed, of course??
On Wed, 10/8/2025 7:01 AM, Daniel70 wrote:
Surely this can't be so .... or has Copilot just not completed the process??
You can make up cases and ask the AI for a result.
The idea of making my stupid cases, is just to get it
to dump the names of a representative set of possibilities.
To move a file can:
1) Require deleting it with a change journal event,
then create it with a second change journal event.
The AI tells us there is no single-event Move type for the job.
There is a tendency in computer systems designs to use
atomic events rather than "do fancy stuff". There is a lot of
fancy stuff we could do, which in the end we don't do.
2) Moves can be orchestrated by the Name Change set of change journal events.
Now, you have to prepare your set of file names, and then
figure out which of those cases apply. Take the actual move
command that demonstrated a problem and get the AI description
of how that would be coded.
The journal dumps I've tried, at some point the design must
have changed. I didn't make a fetish out of this. Like at
one time, you could see a write-file event dumped, for
every 256KB or so of data. I don't think that scheme was
in the latest try I made of a dump.
******************
CoPilot Question
In the NTFS change journal, has the design of the journal events been a
constant with time or did the change journal design or representation change over the years ?
CoPilot Answer
The NTFS Change Journal - also known as the USN Journal - has evolved over time,
though its core purpose has remained consistent: to efficiently track
changes to files and directories on an NTFS volume.
### ?? Evolution of the Change Journal Design
Here?s how its design and representation have changed over the years:
#### 1. **Initial Introduction (Windows 2000 / NTFS 3.0)**
- The Change Journal was introduced with NTFS 3.0.
- It stored records in a metafile called `$Extend\$UsnJrnl`.
- Each record included:
- A 64-bit Update Sequence Number (USN)
- File reference number
- Reason flags (bitmask indicating the type of change)
- Timestamp
- File name
#### 2. **USN_RECORD Structure Versions**
- Over time, Microsoft introduced new versions of the `USN_RECORD` structure:
- **V2**: Used in early implementations (Windows 2000, XP, etc.)
- **V3 and V4**: Introduced in later versions of Windows to support new features and metadata
- These versions added fields like extended reason flags, source info, and more precise timestamps.
#### 3. **Bit Flags Expansion**
- The `Reason` field uses bit flags like `USN_REASON_DATA_OVERWRITE`, `USN_REASON_FILE_CREATE`, etc.
- New flags were added over time to reflect more granular changes (e.g., file renames, ACL changes).
#### 4. **Performance and Scalability Enhancements**
- As file systems grew to support millions of files, the journal?s internal mechanisms were optimized for speed and reduced overhead.
- Journals became more configurable (e.g., size limits, retention policies).
#### 5. **Integration with New Features**
- Windows features like **File History**, **Windows Search**, and **Backup utilities** began leveraging the Change Journal.
- This led to more robust APIs and better documentation for developers.
---
### ? Summary
While the fundamental concept of logging file system changes has stayed the same,
the **structure**, **metadata**, and **integration points** of the NTFS Change Journal
have evolved to meet the demands of modern systems. It?s a great example of a foundational technology quietly adapting behind the scenes.
Would you like to dive into the specifics of the USN_RECORD structure versions
or how backup tools use the journal today? **********************************8
Paul
| Sysop: | Tetrazocine |
|---|---|
| Location: | Melbourne, VIC, Australia |
| Users: | 13 |
| Nodes: | 8 (0 / 8) |
| Uptime: | 148:48:04 |
| Calls: | 177 |
| Files: | 21,502 |
| Messages: | 79,014 |
{kind=link}
{kind=link}